Interpreter to program, który czyta i analizuje kod programu napisanego w jednym języku i na bieżąco go wykonuje.
Przykładowe interpretery, to:
Kompilator to program, który tłumaczy kod napisany w jednym języku, nazywanym językiem źródłowym na równoważny mu kod napisany w innym języku nazywanym językiem wynikowym. Proces tłumaczenia nazywamy kompilacją.
Zwykle praca kompilatora składa się z następujących etapów:
- analizy leksykalnej
- wykonania poleceń preprocesora
- analizy składniowej (parsowania)
- analizy semantycznej
- optymalizacji kodu
- generowania kodu wynikowego
Kodem wynikowym nie zawsze jest kod maszynowy. Na przykład kompilator języka JAVA tłumaczy kod programu napisanego w JAVA na kod pośredni zrozumiały dla wirtualnej maszyny.
W przypadku języków C/C++ językiem wynikowym jest kod maszynowy. Nie zawiera on jednak kompletnej informacji, wystarczającej do uruchomienia i wykonania tego kodu maszynowego w środowisku systemu operacyjnego. Potrzebny jest jeszcze program zwany linkerem.
Linker (konsolidator) to program, którego zadaniem jest połączenie skompilowanych niezależnie jednostek translacji w gotowy do wykonania program.
Często większe programy dzielimy na mniejsze części, które są kompilowane oddzielnie. Pozwala to na:
- zwiększenie przejrzystości kodu
- ułatwia pracę zespołową
- ułatwia wykrywanie błędów (szukamy ich w mniejszych plikach)
- przyspiesza kompilację - nie musimy kompilować jednego wielkiego programu, tylko ten, w którym wprowadziliśmy zmiany
W kompilowanej jednostce translacji możemy korzystać z bibliotek (na przykład z biblioteki standardowej).
Zadaniem linkera jest połączenie wszystkich części składowych w jeden program wykonywalny. Nawet, jeśli kod naszego programu jest zawarty w jednym pliku źródłowym, proces generowania końcowego kodu maszynowego jest rozbity na kompilację i linkowanie.
Przykład - pusty plik źródłowy - poprawna kompilacja, ale mamy błąd linkera.
- Najprostszy kompletny program w języku C musi zawierać definicję funkcji main.
- przed funkcją main musi pojawić się słowo kluczowe int (zgodnie ze standardem języka C)
- po nazwie main występują nawiasy, w których opcjonalnie można podać listę argumentów formalnych - będzie o tym mowa pod koniec wykładu
- po nawiasach okrągłych następuje ciało funkcji main ujęte w nawiasy wąsiaste
- Ciało funkcji main składa się z ciągu instrukcji zapisanego zgodnie ze składnią i semantyką języka C.
Poniżej jest przedstawiony najprostszy poprawny program w języku C - oczywiście on "nic" nie robi.
int main() { }
Słowo "nic" podaliśmy w cudzysłowie, gdyż uruchomienie każdego programu, nawet pustego, powoduje utworzenie procesu realizującego ten program. System operacyjny musi wykonać sporo operacji aby taki proces uruchomić.
Przykład - najprostszy program.
Programy komputerowe są zapisywane w językach, które nie są językami naturalnymi człowieka. W sytuacji, gdy w programie implementujemy skomplikowane algorytmy, kod programu może stać się mało czytelny bez dodatkowych komentarzy. Co więcej, sam autor programu po pewnym czasie ma problemy ze zrozumieniem, co właściwie robi napisany przez niego program (sam wielokrotnie tego doświadczyłem;)
Komentarz to fragment kodu źródłowego, który jest ignorowany przez analizator semantyczny kompilatora. Są to informacje, które autor programu pozostawia dla osób czytających kod programu.
W języku C/C++ komentarze definiujemy za pomocą:
- dwuznaków /* */ - każdy znak zawarty pomiędzy tymi dwuznakami jest komentarzem
- za pomocą dwuznaku // - wszystkie znaki następujące po tym dwuznaku aż do końca linii są traktowane jako komentarz
- niektóre kompilatory pozwalają na zagnieżdżanie komentarzy
/* Autor: Daniel Wilczak Data ostatniej modyfikacji: 9.X.2010 Program ilustrujący stosowanie komentarzy */ int main() { // tutaj powinna się znaleźć właściwa treść programu }
Analizator składniowy dopuszcza właściwie dowolne stosowanie białych znaków (spacji, tabulacji, znaków końca linii).
int main ( ) { }
Powyższy program jest poprawnym kodem w C - pytanie tylko, czy jest czytelny dla człowieka?
W celu zwiększenia czytelności kodu stosuje się różnego rodzaju wcięcia
int main() { printf("witaj w programie odliczacz"); int i=10; while(i) { printf("odliczam %d\n",i--); } }
Inny schemat wcięć nawiasów oznaczających bloki {}
int main(){ printf("witaj w programie odliczacz"); int i=10; while(i){ printf("odliczam %d\n",i--); } }
Wybór metody formatowania kodu, jak i głębokość stosowanych wcięć, zwykle zależy od indywidualnych preferencji programisty. Czasem sposób formatowania określony jest przez reguły przyjęte w zespole programistycznym.
Każdy programista popełnia błędy. Najtrudniej jest wykryć i naprawić:
- błędy wykonania programu, czyli takie, które objawiają się dopiero po uruchomieniu skompilowanego programu (program zawiesza się, doprowadza do niepożądanych sytuacji).
- błędy logiczne - program kompiluje się i wykonuje, ale zwraca błędne wyniki.
Najprostsze rodzaje błędów to te sygnalizowane przez kompilator lub linker.
- Błędy kompilacji pojawiają się wtedy, gdy program jest napisany niezgodnie ze składnią języka. Kompilacja jest wtedy przerywana a programista jest informowany o przyczynie wystąpienia błędu (log kompilacji)
prog.c:3:1: error: 'sd' was not declared in this scope
- ostrzeżenia (Warnings) - program jest napisany zgodnie ze składnią języka i kompilacja nie jest przerywana, ale kompilator zauważył "podejrzany" fragment kodu, który może być ukrytym błędem logicznym.
Na przykład:- kompilator może wyświetlić ostrzeżenie, jeśli w programie deklarujemy, że będziemy korzystać z pewnych zasobów (np. zmiennej) a tego nie robimy
- jeśli sprawdzamy warunek, który zawsze jest prawdziwy lub fałszywy
- jeśli używamy zasobów, które nie były zainicjalizowane, czyli mogą być w nieokreślonym stanie (np. niezainicjalizowana zmienna)
prog.c:3:7: warning: unused variable 'i'prog.c:6:8: warning: 'j' is used uninitialized in this function - Błędy linkowania mogą być zgłoszone przez linker w czasie konsolidacji. Zwykle oznaczają one, że nie dostarczyliśmy linkerowi wszystkich niezbędnych części do wygenerowania kompletnego kodu maszynowego programu wykonywalnego.
Na przykład:- brak funkcji main w programie
Identyfikatory (nazwy) są stosowane do nazywania zmiennych, funkcji, typów itp. W języku C/C++ identyfikatorem może być dowolny ciąg liter (alfabetu angielskiego), cyfr oraz znaków podkreślenia przy czym
identyfikator nie może być słowem kluczowym języka (o tym za chwilę)
Przykłady poprawnych identyfikatorów:
- i
- stanKonta
- stanKonta1
- _stan_konta_
- _stanKonta_1
- _1_stanKonta
- bardzo_dlugi_opisowy_identyfikator
- bardzoDlugiOpisowyIdentyfikator
Dobrze dobrane identyfikatory:
- znacznie podnoszą czytelność kodu
- ułatwiają wyszukiwanie i naprawianie błędów
- świadczą o wysokiej kulturze programistycznej autora kodu
Często stosuje się pewne konwencje nazywania zmiennych (tzw. notacja węgierska).
Wielkość liter ma znaczenie - licznik, Licznik, lIcZnIk to trzy różne identyfikatory.
Słowa kluczowe to zastrzeżone słowa, które definiują składnię języka. Jak już zaznaczyliśmy wcześniej, nie mogą być one używane jako identyfikatory.
Poniższa tabela przedstawia zbiór słów kluczowych języka C/C++.
| and | and_eq | asm | auto | bitand |
| bitor | bool | break | case | catch |
| char | class | compl | const | const_cast |
| continue | default | delete | do | double |
| dynamic_cast | else | enum | explicit | export |
| extern | false | float | for | friend |
| goto | if | inline | int | long |
| mutable | namespace | new | not | not_eq |
| operator | or | or_eq | private | protected |
| public | register | reinterpret_cast | return | short |
| signed | sizeof | static | static_cast | struct |
| switch | template | this | throw | true |
| try | typedef | typeid | typename | union |
| unsigned | using | virtual | void | volatile |
| wchar_t | while | xor | xor_eq |
Zmienna to nazwany obszar pamięci komputera. Nazwa zmiennej musi być poprawnym identyfikatorem. Możemy użyć tej nazwy do operacji na obszarze pamięci, który ta zmienna nazywa.
int i; // linia 1 i=3; // linia 2 float z=19.5; // linia 3 float g = z*i; // linia 4
- W powyższym przykładzie użyliśmy dwóch słów kluczowych: int oraz float.
- Linia pierwsza programu to deklaracja i definicja zmiennej o nazwie i. Zmienna ta będzie nazywać obszar pamięci, najprawdopodobniej o rozmiarze 32 bitów, który jest przeznaczony do przechowywania liczb całkowitych od około -2 mld do 2 mld (szczegóły później). Należy podkreślić, że przy takiej definicji pamięć ta może zawierać przypadkową wartość.
- Linia druga to operacja na pamięci nazwanej i. Instrukcja ta oznacza zapisanie tej w pamięci liczby 3.
- Linia trzecia, to definicja zmiennej typu float połączona z inicjalizacją, czyli nadaniem wartości początkowej 19.5. Typ float określa liczbę zmiennoprzecinkową kodowaną na 32 bitach pamięci. Typ float pozwala na przechowywanie liczb z dokładnością do około siedmiu cyfr znaczących w systemie dziesiętnym.
- Linia czwarta to deklaracja i definicja zmiennej g połączonej z inicjalizacją. Najpierw zostanie obliczona wartość wyrażenia po prawej stronie (z*i = 19.5*3 = 58.5), a później ta wartość zostanie użyta do zainicjalizowania zmiennej g
Dotychczasowe programy przykładowe nigdy nie wyświetlały informacji o wykonanych działaniach. Aby umożliwić wypisywanie wartości zmiennych na ekran potrzebujemy skorzystać z operacji wejścia-wyjścia.
Każdy język wysokiego poziomu dostarcza podstawowych funkcji do realizacji operacji wejścia-wyjścia. Na razie, nie wchodząc w szczegóły, przyjmijmy, że:
- aby skorzystać z operacji wejścia-wyjścia trzeba dodać do naszego programu linie nr 1 i 2 (tutaj mamy mały dodatek C++, ale na razie nie chcę omawiać składni funkcji printf)
- aby wypisać tekst na ekran, używamy instrukcji jak w linii 3
- aby wypisać na ekran wartość zmiennej, używamy instrukcji jak w linii 4
- aby "przejść do nowej linii", używamy instrukcji jak w linii 5
- operacje wypisywania tekstu, zmiennej i znaku końca linii można ze sobą dowolnie łączyć - tak jak to pokazano w linii 6
#include <iostream> // linia 1 using namespace std; // linia 2 int main() { int i=0; cout << "Zmienna i: "; // linia 3 cout << i; // linia 4 cout << endl; // linia 5 int j=10; cout << "j=" << j << endl; // linia 6 }
Przykład - program z wypisaniem wartości na ekran.
Typ zmiennej to w szczególności sposób, w jaki interpretowana jest pamięć określona przez tą zmienną. Widzieliśmy już, że 32-bity pamięci mogą raz tworzyć liczbę całkowitą (int), a innym razem liczbę zmiennoprzecinkową (float).
W C/C++ typy podstawowe (wbudowane) dzielimy na:
- całkowite - służą do przechowywania liczb całkowitych w różnych zakresach. Na przykład: short, int, long
- zmiennopozycyjne - służą do przechowywania liczb ułamkowych: float, double
- boolowskie (logiczne) - typ bool służy do przechowywania wartości logicznych: true, false
- znakowe - służą do przechowywania kodów znaków: char, wchar_t
Przykład - typy podstawowe i operacje na nich.
Język C/C++ dostarcza podstawowych operatorów arytmetycznych:
- operator + oznacza dodawanie
- operator - oznacza odejmowanie
- operator * oznacza mnożenie
- operator / oznacza dzielenie
- operator % oznacza resztę z dzielenia
- operator % można stosować tylko do liczb całkowitych
- operator / można stosować do liczb całkowitych, ale w wyniku dzielenia otrzymujemy część całkowitą z dzielenia
Powstaje pytanie, jak zachowuje się program w przypadku wykonania dzielenia przez zero
- operacja dzielenia przez zero dla typów całkowitych powoduje sygnalizację błędu i przerwanie programu
- operacja dzielenia przez zero dla typów zmiennoprzecinkowych wykonuje się bez sygnalizacji błędu i zwraca nieskończoność
- operacja dzielenia zera przez zero dla typów zmiennoprzecinkowych wykonuje się bez sygnalizacji błędu i zwraca nan (not a number)
Wyrażenie powstałe w wyniku użycia operatorów arytmetycznych, np. a*b+c(d+a) nazywamy wyrażeniem arytmetycznym.
Przykład - operatory arytmetyczne i dzielenie przez zero.
Język C/C++ pozwala modyfikować pewne typy danych przy pomocy tak zwanych specyfikatorów: short, long, signed i unsigned.
Specyfikatory short, long
- Sugerują pojemność (dopuszczalny zakres liczb) odpowiednio niższą i wyższą niż typ podstawowy.
- To jaka rzeczywiście będzie pojemność zależy od implementacji
- Język C/C++ wymaga jedynie, by
- short int zajmował minimum 16 bitów
- long int zajmował minimum 32 bity
- pojemność typu ze specyfikatorem short była nie większa niż typu podstawowego
- pojemność typu ze specyfikatorem long była nie mniejsza niż typu podstawowego
- Oba mogą być stosowane do typu int, a tylko drugi do typu double
Specyfikatory signed, unsigned
- Określają czy jeden bit ma być przeznaczony na znak czy też nie. Wpływa to na pojemność typu.
- Mogą być stosowane do typów char i int.
Przykład - rozmiar i zakres poszczególnych typów
W programach (dosyć często) używamy wielkości, o których wiadomo, że nie powinny się zmieniać. Typowym przykładem jest liczba π.
Możemy oczywiście zastąpić każde wystąpienie π przez np. 3.14. Rozwiązanie to ma jednak bardzo poważną wadę - jeśli uznamy, że wielkość ta powinna być podana z inną dokładnością, to będziemy musieli przeglądnąć cały program i wprowadzić odpowiednią zmianę.
Powracając do przykładu z liczbą π - możemy zdefiniować stałą pi i wykorzystywać ją tak jak każdą inną zmienną z jednym zastrzeżeniem - nie można przypisać nowej wartości do stałej
const float pi = 3.14; float promien = 3; float poleKola = pi*r*r; float obwodKola = 2*pi*r;
Próba przypisania nowej wartości do takiej zmiennej skończy się błędem kompilacji. Oznacza to w szczególności, że takie zmienne muszą być od razu zainicjalizowane
const float pi; // BŁĄD (na ogół) stała niezainicjalizowana prog.cpp:3:15: error: uninitialized const 'pi'
Użycie zmiennej z modyfikatorem const ma wiele zalet
- przejrzystość kodu - jawne odwołanie do nazwy zmiennej pi mówi nam, co tak naprawdę jest wykorzystywane w programie. Wpisana "na sztywno" wartość 3.14 może być równie dobrze kursem EUR/PLN.
- modyfikator const gwarantuje, że kompilator sprawdzi i zasygnalizuje wszelkie próby zmiany takiej zmiennej
const float pi=3.14; pi = 3.1415; prog.cpp:4:8: error: assignment of read-only variable 'pi'
- w przypadku konieczności zmiany wartości stałej (np. zwiększenia dokładności z jaką podajemy π) wystarczy to zrobić w jednym miejscu programu
- pomimo użycia modyfikatora const można zmienić wartość takiej zmiennej (drobna sztuczka) - tylko po co?
- w przyszłości przekonamy się, że w pewnych sytuacjach wartość zmiennej z const musi być nadawana w innym miejscu programu niż jej deklaracja (np. lista inicjalizacyjna w klasach)
Powiedzieliśmy już, że zmienne to nazwane komórki pamięci. Należy rozróżnić dwa aspekty związane ze zmiennymi:
- czas życia zmiennej - jest to czas, w którym komórki pamięci są zarezerwowane dla tej zmiennej i nie zostaną przydzielone innej zmiennej
- zakres ważności zmiennej - jest to zbiór tych instrukcji programu, w których zmienna jest dostępna za pomocą identyfikatora.
Na ogół czas życia zmiennej nie pokrywa się z czasem wykonywania instrukcji, w których zmienna jest widoczna (dostępna za pomocą identyfikatora). Szczegóły przedstawimy w dalszej części kursu. Teraz odnotujemy tylko dwie podstawowe sytuacje:
- zmienna może być zadeklarowana globalnie, czyli poza wszystkimi blokami programu
- zmienna może być zadeklarowana lokalnie, czyli wewnątrz jakiegoś bloku programu
Podkreślamy, że powyższa lista nie jest kompletna - szczegóły będą w dalszej części kursu.
int z; // zmienna globalna, inicjalizowana zerem int main() { int k; // zmienna lokalna, może mieć losową wartość }
- zmienne globalne są inicjalizowane domyślnymi wartościami typu jeszcze przed rozpoczęciem wykonywania programu. W szczególności zmienne globalne typu liczbowego będą zainicjalizowane zerem.
- zmienne lokalne nie są inicjalizowane! Oznacza to, że mogą mieć zupełnie losową wartość, zależną od tego, co pozostało w pamięci po poprzednio wykonywanych instrukcjach (możliwe, że innego programu)
- Zmienna typu bool może przyjmować tylko dwie wartości: true (prawda) albo false (fałsz).
- Typ bool wprowadzono do języka C++ stosunkowo niedawno.
- Język C nie stosuje specjalnego typu do przechowywania zmiennych logicznych.
- W języku C przyjmuje się, że liczba zero każdego typu reprezentuje fałsz, a liczba niezerowa prawdę.
- Dla zachowania kompatybilności z językiem C przyjęto zasadę, że wszędzie gdzie powinien być użyty typ bool, a użyto liczby, dokonywana jest konwersja zera na false, a wartości różnej od zera na true
- Przy wypisywaniu do strumienia wartość false jest reprezentowana jako zero, a true jako jeden.
Język C/C++ definiuje podstawowe operatory (bramki) logiczne. W szczególności:
- operator && oznacza koniunkcję, w C++ można użyć słowa kluczowego and
- operator || oznacza alternatywę, w C++ można użyć słowa kluczowego or
- operator ! oznacza negację, w C++ można użyć słowa kluczowego not
- operator ^ oznacza alternatywę wykluczającą, w C++ można użyć słowa kluczowego xor
Przykład użycia operatorów logicznych.
Do budowania wyrażeń logicznych używa się również operatorów porównania:
- operator > oznacza relację "większe"
- operator >= oznacza relację "większe lub równe"
- operator < oznacza relację "mniejsze"
- operator <= oznacza relację "mniejsze lub równe"
- operator == oznacza relację "równe"
- operator != oznacza relację "różne"
Operatory te zwracają prawdę lub fałsz, w zależności od tego, czy porównywane argumenty są w relacji, czy nie.
Przykład użycia operatorów porównania.
Operatory podobnie jak w matematyce nie zawsze są wykonywane w kolejności od lewej do prawej, ale mają określone priorytety.
Poznane do tej pory operatory wykonają się w następującej kolejności
- *, / ,%
- +, -
- >>, << (operacje na strumieniach)
- >, >=, <, <=
- ==, !=
- &&
- ||
Pełną listę można znaleźć np. na stronie cppreference.com.
Aby zwiększyć czytelność kodu warto stosować nawiasy nawet jeżeli domyślna kolejność jest taka jaką chcieliśmy.
Na przykład kod
if(a+2<c||b*2==c&&a*b%c) cout<<a+b*c<<a-b/c<< endl;
if( (a + 2 < c) || ((b * 2 == c) && (a * b % c)) ) cout << (a + b * c) << (a - b/c) << endl;
Każdy język programowania udostępnia instrukcje warunkowe. Pozwalają one na sterowanie przebiegiem wykonywania programu w zależności od wartości wyrażenia logicznego.
Podstawowa instrukcja warunkowa to if, a jej podstawowa składnia jest następująca:
if(warunek) instrukcja
Instrukcja warunkowa if-else pozwala podać instrukcje, które będą wykonane, jeśli warunek ma wartość fałsz
if(warunek) instrukcja1 else instrukcja2
W instrukcji warunkowej to co występuje po if lub else może być pojedynczą instrukcją. Jeżeli chcemy wstawić tam więcej instrukcji musimy zgrupować je w blok ujęty w nawiasy wąsiaste.
if(warunek) { instrukcja1 intrukcja2 ... } else { instrukcja3 instrukcja4 ... }
Przykład - instrukcja warunkowa if-else
Czasami zapis wyrażenia można znacznie uprościć stosując
Jest on postaci
warunek ? wyrazenie1 : wyrazenie2 ;
- Jeżeli warunek ma wartość true zwracana jest wartość wyrażenia wyrazenie1, w przeciwnym wypadku zwacany jest wartość wyrażenia wyrazenie2.
- Wartości wyrażeń wyrazenie1 i wyrazenie2 powinny być tego samego typu (tak naprawde wystarczy, że istnieje niejawna konwersja do wspólnego typu).
- Jeżeli chcemy wykonać więcej niż jedna instrukcję aby wyliczyć wartość wyrażenia, możemy zamieścić listę instrukcji oddzielonych przecinkami. Wtedy wartością zwracaną jest wartość otrzymana z ewaluacji ostatniej instrukcji.
int liczbaDniWLutym = czyPrzestepny(rok) ? 29 : 28;
double delta = b*b - 4*a*c; // liczba rozwiazan rownania a*x^2 + b*x + c = 0 int liczbaRozwiazan = (delta>0) ? 2 : ((delta==0) ? 1 : 0 );
Pętle to instrukcje używane, gdy zachodzi potrzeba wielokrotnego wykonywania tego samego fragmentu kodu, najczęściej dla różnych danych wejściowych.
Podstawowa pętla while ma składnię
while(warunek) instrukcja;
Instrukcja wykonywana w pętli może być instrukcją złożoną (blokiem instrukcji).
W pętli while najpierw testowany jest warunek, a instrukcja jest wykonywana tylko wtedy, gdy warunek jest spełniony. Może się więc zdarzyć, że instrukcja nie zostanie nigdy wykonana.
Pętla do-while jest bardzo podobna. W przypadku pętli do-while instrukcja wykona się co najmniej raz, później sprawdzany jest warunek.
do instrukcja while(warunek);
Przykład użycia pętli do-while
Pętla for jest najczęściej wykorzystywana, gdy z góry wiadomo ile przebiegów pętli ma się wykonać. Składnia pętli for to:
for(inicjalizacja; test; inkrementacja) instrukcja // przykład for(i=0; i<20; i=i+2) { cout << i << endl; }
Instrukcja switch to instrukcja warunkowa. Wykorzystujemy ją najczęściej gdy potrzebujemy wykonać różne instrukcje dla różnych w zależności od wartości pewnej zmiennej całkowitej.
Składnia instrukcji switch to:
switch(wyrazenie_calkowitoliczbowe) { case w1 : instrukcja1 case w2 : instrukcja2 ..... case wN : instrukcjaN default: instrukcja }
- Wartości w1, w2, ... muszą być całkowitoliczbowe i znane w czasie kompilacji.
- Najpierw obliczana jest wartość wyrażenia całkowitoliczbowego. Jeśli wartość ta jest równa wK, to sterowanie programu przeniesione jest do pierwszej instrukcjaK
- jeśli obliczone wyrażenie całkowitoliczbowe jest różne od wszystkich wK, to sterowanie jest przeniesione do instrukcji następującej po default
- Przypadki wK mogą być umieszczone w dowolnej kolejności. Należy jednak pamiętać, że jeśli wyrażenie całkowitoliczbowe będzie równe wK, to zostaną również wykonane wszystkie instrukcje następujące po instrukcjaK
- wartości wK nie mogą się powtarzać.
- można umieścić sekcję default w dowolnym miejscu lub całkiem opuścić. Jest on opcjonalny.
Instrukcja continue może być użyta tylko wewnątrz pętli. Powoduje ona:
- przerwanie wykonywania bieżącej iteracji pętli
- w przypadku pętli while i do-while powoduje skok do testowania warunku
- w przypadku pętli for powoduje skok do instrukcji inkrementacji, a następnie testowania warunku
Przykład użycia instrukcji continue
Instrukcja break może być użyta wewnątrz pętli lub wewnątrz instrukcji switch. Powoduje ona przerwanie wykonywania pętli lub instrukcji switch i skok do pierwszej instrukcji za pętlą lub switch.
Instrukcja switch jest najczęściej używana w połączeniu z break.
Przykład użycia instrukcji switch
Każda instrukcja może być poprzedzona etykietą.
etykieta: instrukcja
Etykietą może być dowolny identyfikator. Służą one do oznaczania miejsc w programie.
Instrukcja goto to instrukcja skoku. Powoduje ona przeniesienie wykonywania programu do miejsca oznaczonego etykietą. Nadużywanie instrukcji goto świadczy o bardzo złym stylu programowania. Są jednak sytuacje (raczej wyjątkowe), gdzie instrukcja goto może być użyteczna. Jest to wyjście z bardzo zagnieżdżonej pętli.
Składnia instrukcji goto to:
goto etykieta;
Przykład - wyjście z pętli za pomocą goto
Często program musi przechowywać i przetwarzać wiele elementów takiego samego typu. Mogą to być np. klienci firmy, numery telefonów, itp. Jest wiele (często całkiem skomplikowanych) sposobów przechowywania takich zbiorów danych. Jednym z najprostszych jest użycie tablic.
Tablicę możemy interpretować jako zbiór ponumerowanych obiektów tego samego typu. Mają one wspólną nazwę - jest to nazwa tablicy - a każdy element tego zbioru jest jednoznacznie wyznaczany za pomocą swojego numeru.
Instrukcja
int silnia[12];
- oznacza definicję tablicy złożonej z 12 elementów
- elementami tej tablicy będą liczby całkowite typu int
Dostęp do kolejnych elementów tablicy uzyskujemy za pomocą nazwy tablicy i numeru elementu. W poniższym przykładzie czwartemu elementowi tablicy silnia przypiszemy wartość 6. Pamiętajmy, że elementy są indeksowane od zera, zatem silnia[3] jest czwartym elementem tablicy.
silnia[0] = 1; // pierwszy element tablicy silnia[3] = 6;
Ważne uwagi:
- Kompilator języka C/C++ nie sprawdza, czy podajemy poprawny numer elementu tablicy (np. ujemny)
- podanie niepoprawnego numeru elementu tablicy będziemy nazywać wyjściem poza tablicę
- wyjście poza tablicę jest przyczyną wielu błędów, często trudnych do wykrycia. Może się zdarzyć, że program kompiluje się i wykonuje bez błędów, ale zwraca niepoprawne wyniki.
int tablica[10]; // definicja tablicy tablica[10] = 7; // BLAD!!! // modyfikujemy 11 element tablicy
Przykład - przekroczenie zakresu tablicy
Przykład - wyliczanie symbolu Newtona
Jeśli tablica jest zadeklarowana jako zmienna globalna, to zostanie ona uzupełniona zerami jeszcze przed rozpoczęciem wykonywania programu.
Tablice zadeklarowane lokalnie mają losowe wartości. Nie można zakładać, że tablica jest wypełniona zerami. Tablicę, zarówno lokalną jak i globalną, można zainicjalizować w momencie deklaracji.
int wzrost[5]={178,191,165,180,170};
Powyższa instrukcja oznacza definicję tablicy o nazwie wzrost oraz inicjalizację wszystkich elementów tablicy podanymi w nawiasach wąsiastych wartościami.
Uwagi:
- wartości użyte do inicjalizacji nie muszą być znane w czasie kompilacji - zobacz przykład poniżej
- wartości inicjalizujących może być mniej niż elementów tablicy. Pozostałe wartości zostaną uzupełnione zerami. W poniższym przykładzie będzie zainicjalizowane wiek[3]=0 oraz wiek[4]=0
int wiek[5]={5,7,10};
- jeśli wartości inicjalizujących jest więcej niż rozmiar tablicy, to kompilator zgłosi błąd.
int wiek[5]={6,7,3,1,4,5,3}; // BLAD!!! za duzo elementow
-
jeśli tablica jest inicjalizowana, to w definicji można pominąć jej wielkość. Kompilator wygeneruje tablicę o wielkości równej ilości elementów na liście inicjalizacyjnej.
Powyżej kompilator wygeneruje kod tworzący tablicę 3-elementową.
int wiek[]={5,7,10};
Przykład - inicjalizacja tablic.
Język C/C++ dostarcza typów wbudowanych, które służą do przechowywania znaków (liter, symboli, itp). Są to typy:
- char - jednobajtowa zmienna, która przechowuje kod ASCII znaku (standard C mówi tylko, że ma to być nie mniej niż 8 bitów)
- wchar_t - (wide character, 16 lub 32 bity) jako typ wbudowany tylko w C++ (i to od niedawna). Jest to typ pozwalający na przechowywanie rozszerzonego zestawu znaków (unicode).
Znaki możemy inicjalizować wartością liczbową (kodem ASCII) bądź też podając znak w apostrofach - zostanie on przekonwertowany na odpowiadający mu kod ASCII.
char z=65; // kod ASCII litery A char w='A';
Niektóre znaki są bardzo często wykorzystywane, chociaż nie odpowiada im żaden znak na klawiaturze. Znaki te możemy wprowadzić do kodu źródłowego podając jawnie kod ASCII takiego znaku, lub też (zalecane) używając znaków specjalnych. Wybrane znaki specjalne:
- \t - oznacza znak tabulacji
- \n - oznacza znak końca linii
- \\ - oznacza lewy ukośnik (backslash) \
- \0 - zero, koniec napisu (będzie na następnym slajdzie)
Napisy w języku C/C++ to po prostu tablice znaków. Przyjęto umowę, że koniec napisu wskazuje znak o kodzie zero (nie mylić ze znakiem zero, który ma kod 48).
Jest to bardzo użyteczna konwencja, gdyż wielkość tablicy wcale nie musi odpowiadać długości napisu. Typowa sytuacja to taka, w której deklarujemy tablicę o pewnej wielkości (bufor), po czym zapisujemy do niego tekst, np. wprowadzony przez użytkownika. Na ogół tekst jest znacznie krótszy od wielkości bufora.
char napis[] = {'D','a','n','i','e','l','\0'};
Napisy podawane w cudzysłowach
Podawanie napisów tak jak powyżej, chociaż formalnie poprawne, jest bardzo uciążliwe. Język C/C++ pozwala na wprowadzanie napisów przy pomocy znaków cudzysłowu. Każdy ciąg znaków pomiędzy znakami cudzysłowu jest napisem z automatycznie dodanym kończącym zerem.
Powyższa deklaracja tablicy napis jest funkcjonalnie równoważna z
char napis[] = "Daniel";
Znaki specjalne w cudzysłowach
Wprowadzając napis za pomocą znaków cudzysłowu możemy użyć w nim znaków specjalnych, na przykład
char napis[] = "Wykladowca:\n\tDaniel Wilczak";
Wydrukowanie tego napisu (np. za pomocą strumienia cout) da w wyniku
Wykladowca:
Daniel Wilczak
Tablicę znakową można zainicjalizować w momencie deklaracji. Późniejsza zmiana NIE JEST MOŻLIWA przy pomocy operatora podstawienia. O sposobach modyfikacji powiemy w dalszej części kursu.
char napis[] = "Daniel"; napis = "Roman"; //BLAD
Często jest potrzeba przechowywania podobnych danych indeksowanych (numerowanych) nie jedną liczbą, a wieloma. Możemy to zilustrować za pomocą arkusza kalkulacyjnego - aby odnieść się do komórki w arkuszu musimy podać numer wiersza i kolumny.
W języku C/C++ tablica dwuwymiarowa to po prostu tablica tablic, czyli elementami jednej tablicy są inne tablice. W przypadku arkusza kalkulacyjnego:
- każdy wiersz jest tablicą komórek
- arkusz to tablica wierszy (czyli tablica tablic komórek)
Formalnie można tworzyć tablice indeksowane jeszcze większą ilością liczb (tablice tablic tablic, itp). Deklaracja tablicy dwuwymiarowej może wyglądać następująco
int arkusz[20][50];
Powyżej zadeklarowaliśmy 20-elementową tablicę, której elementami są tablice 50-elementowe (możemy sobie wyobrazić arkusz wielkości 20 na 50). Elementy takiej tablicy można odczytać lub zmienić podając dwa indeksy w nawiasach kwadratowych:
arkusz[4][5] = 7;
Inicjalizacja tablic wielowymiarowych
Tablice wielowymiarowe możemy inicjalizować za pomocą list inicjalizacyjnych. Musimy oczywiście odpowiednio pogrupować te dane za pomocą nawiasów wąsiastych.
int t[2][4] = {{1,2,3,4},{5,6,7,8}}; int k[3][4] = {{2,4},{3,7,8}}; int z[3][4] = {{2,4,0,0},{3,7,8,0},{0,0,0,0}};
Druga i trzecia deklaracja są sobie równoważne funkcjonalnie. W przypadku podania wielkości tablic, każda z nich zostanie uzupełniona zerami, jeśli danych w liście inicjalizacyjnej jest za mało.
W inicjalizowanej tablicy wielowymiarowej można pominąć jej pierwszy (i tylko pierwszy) rozmiar. Kompilator sam ustali wielkość tablicy na podstawie ilości elementów w liście inicjalizacyjnej. Poniższe dwie deklaracje dają taki sam efekt.
int t[][4] = {{1,2,3,4},{5,6,7,8}}; int z[2][4] = {{1,2,3,4},{5,6,7,8}};
Typowym przykładem użycia tablicy tablic jest tablica napisów. Napis, to tablica znaków. Jeśli na przykład chcemy stworzyć tablicę imion pracowników firmy, to będzie to właśnie tablica tablic znaków.
char imiona[30][32];
Powyżej zadeklarowaliśmy tablicę, w której można zapamiętać 30 napisów (na przykład imion). Możemy ją od razu zainicjalizować
char imiona[30][32] = {"Piotr","Ewa","Marta","Adam"};
Pozostałe elementy tablicy zostaną uzupełnione zerami, co w przypadku napisów oznacza napisy puste.
Gdybyśmy chcieli jednocześnie przechowywać nazwiska pracowników firmy, to możemy stworzyć oddzielną tablicę lub stworzyć tablicę trójwymiarową
char imiona[30][32]; char nazwiska[30][32]; // możemy też stworzyć tablicę trójwymiarową // 30 osob, kazda ma 2 napisy (imie, nazwisko) po 32 znaki char osoby[30][2][32];
Biblioteka standardowa
Wybrane funkcje :
| strlen(napis) | zwraca dlugość napisu, |
| strcpy(cel, zrodlo) | kopiuje napis ze zrodlo do cel. Tablica znakowa cel musi być odpowiednio duża aby pomieścić cały napis wraz z znakiem końca. |
| strncpy(cel, zrodlo, n) | kopiuje maksymalnie n znaków ze zrodlo do cel. Nie dokłada znaku końca napisu. |
| strcat(napis1, napis2) | dopisuje napis2 do konca napis1 Tablica napis1 musi być odpowiednio duża aby pomieścić wynik. |
| strcmp(napis1, napis2) | porównuje dwa napisy leksykograficznie. Zwraca:
|
Przykład - napisy z wykorzystaniem cstring.
Chyba większość programów korzysta z napisów. Operacja na napisach za pomocą tablic znakowych jest wprawdzie wydajna (szybka), ale bardzo uciążliwa. Kod jest podatny na błędy, czasem trudne do wykrycia.
Biblioteka standardowa języka C++ dostarcza typu string. Nie jest to typ wbudowany!
Aby korzystać z typu string należy w programie dołączyć odpowiedni plik nagłówkowy.
#include <iostream> #include <string> // tutaj dołączamy klasę string using namespace std; int main() { string imie; cout << "Przedstaw sie"; cin >> imie; cout << "Witaj " << imie; }
Przykład - napisy z wykorzystaniem typu string.
- Wskaźniki to obiekty, które mogą pokazywać na inne obiekty.
- Zmienna wskaźnikowa to zmienna, przeznaczona do przechowywania wskaźników.
- Wskaźnik przechowuje adres pamięci, pod którym może znajdować się inny obiekt.
Wskaźnik jest typem pochodnym od jakiegoś innego typu. Jeśli T jest typem, to T* jest typem, który może przechowywać adresy obiektów typu T
// deklaracja wskaźnika, // który może przechowywać adresy zmiennych typu int int* p; double* d = 0; char* s;
Wskaźniki puste:
Wskaźnik zawiera pewien adres pamięci - jest to liczba. Przyjęto umowę, że adres 0 oznacza adres pusty - czyli wskaźnika aktualnie nie pokazuje na żaden obiekt.
Operator adresu służy do pobierania adresu zmiennej. Wartość taką możemy przypisać do wskaźnika
int p=10; int* wsk = &p; // & pobierze adres zmiennej p cout << wsk; // na ekranie zobaczymy adres zmiennej p
Operator wyłuskania ma odwrotne działanie. Służy on do odniesienia się do obiektu pokazywanego przez wskaźnik
int p = 10; int q = 20; int* wsk = &p; cout << *wsk; // wydrukujemy p, czyli 10 wsk = &q; // przestawiamy wskaźnik na zmienną q cout << *wsk; // wydrukujemy q, czyli 20
Przykład - operatory adresu i wyłuskania.
Położenie symbolu * przy deklaracji wskaźnika nie ma większego znaczenia. Można użyć każdej z opcji:
int* p; int* p; int * p; int*p;
Można myśleć, że int* jest nowym typem. Nie jest to jednak prawda. Zapis
int* p, q;
deklaruje zmienną wskaźnikową p oraz zwykłą zmienną q typu int. Aby zadeklarować dwie zmienne wskaźnikowe w jednej instrukcji należy obie zmienne poprzedzić symbolem *
int *p, *q;
W takiej sytuacji jest bardziej czytelne, jeśli przykleimy symbol * do nazw zmiennych.
Arytmetyka wskaźników daje równie wielkie możliwości jakie są niebezpieczeństwa związane z jej niepoprawnym używaniem.
Wskaźniki przechowują adresy obiektów. Kompilator wie, jakiego typu jest obiekt pokazywany przez wskaźnik i ile pamięci taki obiekt zajmuje. Pozwala to na wyliczenie jaki jest adres następnego, czy poprzedniego obiektu w pamięci.
Niech T będzie pewnym typem. Jeśli do wskaźnika T* p dodamy liczbę k, to wskaźnik ten przesuwa się o k*sizeof(T) bajtów. Na przykład, po wykonaniu:
int n; int* p = &n; p++;
wskaźnik p pokazuje adres tuż za zmienną n. Zatem zapis p++ w odniesieniu do wskaźnika należy interpretować jako "przesuń się o rozmiar jednego int" a nie o jeden bajt.
- Wskaźniki dają programiście pełną władzę nad całością dostępnej pamięci. Pozwala to na pisanie bardzo szybkich programów oraz korzystanie z zasobów niedostępnych bez ich użycia.
- Kompilator nie sprawdza, czy to, na co pokazuje wskaźnik jest poprawnym obiektem. Niepoprawne użycie wskaźników, a szczególnie arytmetyki wskaźników prowadzi na ogół do trudnych do znalezienia błędów.
Tablice są przechowywane w ciągłym obszarze pamięci tak jak to przedstawiono poniżej.
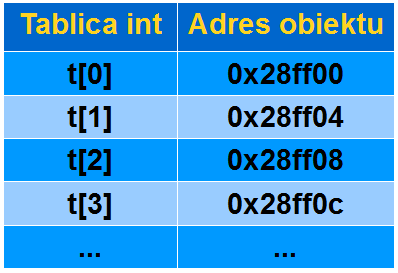
Tablica, to tak naprawdę adres pierwszego elementu tej tablicy. Jest to stały wskaźnik, czyli taki, którego nie można przesuwać. Zawsze będzie pokazywał na pierwszy element tablicy.
Skoro tablica jest stałym wskaźnikiem, to można stosować dla niej arytmetykę wskaźników
int t[] ={0,1,2,3,4,5}; cout << t[2] << endl; cout << *(t+2) << endl;
Ostatnią linię przykładu należy rozumieć tak: przesuń adres pierwszego elementu tablicy o dwa rozmiary obiektu int, a następnie wypisz liczbę, która tam się znajduje.
- Analizator składniowy gcc zamienia każde odwołanie do elementu tablicy t[i] na równoważne mu *(t+i)
- W konsekwencji można równie dobrze napisać i[t], na przykład 3[t] zamiast t[3]
- Chociaż program się skompiluje i będzie działał poprawnie, to NIE ZALECAM stosowania takiej składni.
Przykład - tablica jako wskaźnik
Bardzo często pisząc program nie wiemy, jak dużo obiektów będziemy potrzebowali utworzyć. Na przykład pisząc program dla banku nie możemy zakładać, że bank może obsłużyć co najwyżej 10000 kont. A może 1000000?
Wskaźniki pozwalają na dostęp do dowolnego obszaru pamięci - mogą pokazywać na obiekty, których istnienie nie było znane w czasie kompilacji. W trakcie wykonywania programu możemy zażądać od systemu operacyjnego przydziału pewnej ilości pamięci. Jeśli w systemie jest jeszcze dostępna wolna pamięć, zostanie ona zarezerwowana a jej adres będzie zostanie przekazany do procesu, który zgłosił żądanie przydziału pamięci.
Takie obiekty będziemy nazywać dynamicznymi. Mogą być one powoływane w dowolnym momencie i usuwane z pamięci w każdym innym miejscu programu. Dostęp do takich obiektów mamy tylko za pomocą wskaźników i referencji (o tym za chwilę).
Do alokacji pamięci na stercie można użyć operatora new (to jest z C++).
int* obiekt = new int; int* tablica = new int[50]; int* p= new int[i];
- pierwsza linia przykładu to żądanie zarezerwowania pamięci dla jednego obiektu typu int. Jego adres zostanie zapamiętany w zmiennej wskaźnikowej obiekt
- Druga linia programu przykładu to żądanie zarezerwowania pamięci dla tablicy 50 obiektów typu int
- W trzeciej linii przykładu również żądamy przydziału pamięci - tym razem jej wielkość nie jest znana w czasie kompilacji. Aktualna wartość zmiennej i (typu int) określa, ile pamięci potrzebujemy.
Usuwanie obiektów:
Obiekty zarezerwowane za pomocą new należy oddać do dyspozycji systemu operacyjnego przed zakończeniem programu (w dowolnym momencie, jeśli już przestają nam być potrzebne). Służy do tego operator delete
delete obiekt; delete []tablica; // nie podajemy rozmiaru usuwanej tablicy! delete []p;
Referencje pojawiły się w C++. Referencję możemy traktować jako inną nazwę na już istniejący obiekt. O wielkiej przydatności referencji przekonamy się już niedługo podczas omawiania struktur i funkcji. Na razie zapoznamy się ze składnią.
- Jeśli T jest pewnym typem, to T& określa referencję do typu T
- Zmienną referencyjną, albo krótko referencję, musimy zainicjalizować w momencie jej deklaracji (są od tego wyjątki, np. składowe klas i struktur, które są referencjami inicjalizujemy na liście inicjalizacyjnej).
int n=10; int& ref = n; ref = 20; cout << n; // wypisze 20
Jak to działa?
Referencja to tak naprawdę stały wskaźnik. Składnia referencji zabrania wykonywania operacji znanych dla wskaźników: referencji nie można ustawić na inny obiekt, nie jest dostępna arytmetyka referencji. Po kompilacji (w kodzie maszynowym) referencje i wskaźniki niczym się nie różnią.
Korzystając z referencji świadomie rezygnujemy z pewnych możliwości oferowanych nam przez wskaźniki. W zamian dostajemy:
- łatwiejszą notację - nie musimy używać operatora wyłuskania do odwoływania się do obiektu
- większe bezpieczeństwo - brak arytmetyki dla referencji znacznie utrudnia popełnienie błędów związanych z niepoprawnym odwołaniem do pamięci
-
Deklaracja zmiennej informuje kompilator, że dany identyfikator będzie używany dla obiektów podanego typu. -
Definicja jest poleceniem utworzenia w pamięci komputera obietku stosownego typu powiązanego z daną nazwą. - Pojęcie deklaracji i definicji stosuje się do wszystkich nazw stosowanych w programie
- Pisząc w C/C++
jednocześnie
int wzrost;
- dokonujemy
deklaracji zmiennej: informujemy kompilator, że identyfikator wzrost będzie nazwą dla zmiennej typu int -
definiujemy zmienna rezerwując dla niej pamięć.
- dokonujemy
- Istnieją w C++ sposoby deklarowania zmiennych bez ich definiowania, ale najczęściej łączymy deklarację z definicją.
- W C/C++ wszystkie zmienne muszą być zadeklarowane przed ich pierwszym użyciem.
W wykładzie wprowadzającym (o zmiennych lokalnych i globalnych) wprowadziliśmy dwa podstawowe terminy związane ze zmiennymi - zakres ważności oraz czas życia zmiennej.
- czas życia zmiennej - jest to czas, w którym komórki pamięci są zarezerwowane dla tej zmiennej i nie zostaną przydzielone innej zmiennej
- zakres ważności zmiennej - jest to zbiór tych instrukcji programu, w których zmienna jest dostępna za pomocą identyfikatora.
W tym rozdziale podamy bardziej szczegółową klasyfikację (chociaż ciągle niekompletną!) i informacje odnośnie czasu życia i zakresu ważności zmiennych. Wiedza taka pozwala poprawnie używać różnych typów zmiennych w czasie tworzenia programów oraz uniknąć trudnych do wykrycia błędów logicznych w programach.
Zmienne globalne, to zmienne zadeklarowane poza jakimkolwiek blokiem programu.
int g; //zmienna globalna int main(){ }
Zmienne globalne
- są inicjalizowane wartością domyślną dla danego typu,
- tworzone jeszcze przed rozpoczęciem programu, a niszczone po zakończeniu działania programu.
- czas życia zmiennej globalnej to okres od utworzenia procesu przez system operacyjny, do jego zakończenia
- zakres ważności zmiennej globalnej to wszystkie bloki programu (o ile nie nastąpi jej zasłonięcie)
- nie wiemy w jakiej kolejności będą tworzone zmienne globalne
- to zmienne zadeklarowane wewnątrz dowolnego bloku { ... }
- czas życia takiej zmiennej to czas wykonywania instrukcji bloku, w którym taka zmienna została zadeklarowana. Kompilator po napotkaniu bloku generuje kod, który alokuje pamięć dla wszystkich zmiennych lokalnych tego bloku. Polega to na przesunięciu wskaźnika stosu o wielkość niezbędną do pomieszczenia na stosie wszystkich zmiennych lokalnych.
- zakres widoczności zmiennej, to instrukcje od momentu deklaracji, do końca bloku, w którym zmienna została zadeklarowana. Mamy jednak wyjątek - zmienna może zostać zasłonięta. O tym będzie za chwilę.
{ // 1 .... int a; // 2 { // 3 .... int b; // 4 } // 5 } // 6
W przykładzie powyżej
- czas życia zmiennej a to czas wykonywania instrukcji 1-6
- czas życia zmiennej b to czas wykonywania instrukcji 3-5
- zakres widoczności zmiennej a to blok instrukcji 2-6
- zakres widoczności zmiennej b to blok instrukcji 4-5
Zmienna zadeklarowana wewnątrz bloku może być poprzedzona słowem kluczowym static. W ten sposób deklarujemy zmienne lokalne statyczne.
{ static int a = 10; ... }
Różnią się one od zwykłych zmiennych czasem życia, mianowicie:
- zakres ważności zmiennej lokalnej statycznej jest taki, jak zwykłej zmiennej lokalnej.
- czas życia zmiennej jest lokalnej statycznej taki, jak dla zmiennych globalnych.
- zmienne lokalne statyczne można inicjalizować, ale odbędzie się to tylko raz - w momencie ładowania programu do pamięci.
Po co używać zmiennych lokalnych statycznych?
- Zmienne lokalne statyczne przechowują swoją wartość nawet po opuszczeniu bloku, w którym są zadeklarowane. Zachowują się więc jak zmienne globalne.
- Z drugiej strony nie pozwalają one na dostęp do takiej zmiennej za pomocą jej identyfikatora w innych blokach programu. Oznacza to ochronę tej zmiennej przed jej niepoprawnym (często przypadkowym) użyciem w innych fragmentach programu. Zwykła zmienna globalna jest widoczna wszędzie!
Przykład - użycie zmiennej lokalnej statycznej.
Bardzo ważnym rodzajem obiektów są obiekty tworzone na stercie. W tym przypadku to programista sam decyduje o zakresie ważności i czasie życia obiektu.
Obiekty takie tworzymy (na przykład) przy pomocy operatorów new oraz new[]a usuwamy z pamięci przy pomocy operatorów delete oraz delete[]. W języku C alokację pamięci na stercie wykonuje się za pomocą funkcji bibliotecznych, np. malloc, realloc, itp.
{ int* wsk = new int; .... delete wsk; }
- W podanym przykładzie mamy dwa obiekty
- pierwszy z nich to wskaźnik wsk. Jest to zwykła zmienna lokalna.
- drugi obiekt, to ten utworzony na stercie. Nie ma on swojego identyfikatora, a dostęp do niego mamy za pomocą zmiennej wskaźnikowej.
- Czas życia obiektu utworzonego na stercie, to czas od momentu jego utworzenia przez system operacyjny po użyciu new, do czasu jego usunięcia przez system operacyjny po wykonaniu delete
- zakres ważności zmiennej zależy od konkretnego programu. Zmienna jest ważna dopóty, dopóki jest chociaż jedna zamienna (wskaźnik, referencja), za pomocą której mamy dostęp do tego obiektu
- Obiekty alokowane na stercie nie są usuwane.
- Poprawny program powinien przed zakończeniem wykonywania zwolnić całą pamięć, jaka została zaalokowana na stercie.
- Współczesne systemy operacyjne odzyskują pamięć, która nie została zwolniona, jednak brak zwolnienia pamięci może być przesłanką do poważnych błędów w programie, oraz tak zwanych wycieków pamięci.
- Długo działający proces z wyciekami pamięci może doprowadzić do zajęcia całych zasobów komputera.
Każdy typ wbudowany ma odpowiedni zestaw literałów.
- literałów dziesiętnych: 10, 1234, -158, 0,
- literałów ósemkowych: 012, 02322, -0236, 00,
- literałów szesnastkowych: 0xA, 0X4D2, 0x9e, 0x00.
U aby wskazać, że literał jest typu unsigned int, np. 14U L literał jest typu long int (jest to potrzebne zwłaszcza przy dużych liczbach) np. 12345678901234567890L
- z kropką dziesiętną: 10.0, 1234.5678, 0.0,
- z wykładnikiem : 1.0e1, 1.234567E3, -1.2e-300.
- Literały znakowym jest przeważnie pojedynczy znak ujęty w apostrofy, np. 'A', 'a'.
Najczęściej wartością takiego literału jest kod ASCII danego znaku. - Literały znakowe obejmują także znaki specjalne poprzedzone ukośnikiem: '\n' (znak nowej lini), '\t' znak tabulacji,
- Możemy też wprowadzić kod ósemkowy znaku poprzedzony ukośnikiem np. '\012' lub kod szesnastkowy znaku poprzedzony
\x np. '\xA0. - Aby pokazać, że dany literał jest typu
wchar_t poprzedzamy go przedrostkiem L np. L'Ω'
Literały tekstowe są ciągiem znaków ujętych w cudzysłowy np. "To jest przykładowy tekst\n".
W programie napisanym w C/C++ mogą pojawić się zmienne o takich samych identyfikatorach. Jedynym ograniczeniem jest to, że dwie zmienne o takiej samej nazwie nie mogą być zadeklarowane w tym samym bloku.
Jeśli w bloku zadeklarowano zmienną o identyfikatorze, który był użyty dla innej zmiennej o ważności obejmującej ten blok, to mamy do czynienia z zasłanianiem nazwy zmiennej.
int j=10; int main() { .... int i; for(i=0;i<10;i++) { int j = 5; // zasłaniamy zmienną globalną j .... ::j = 13; // można użyć zasłoniętej zmiennej globalnej // przy pomocy operatora zakresu } }
- W bloku pętli for zmienna lokalna j zasłania zmienną globalną o takim samym identyfikatorze
- Zmienna globalna jest mimo wszystko dostępna, przy pomocy tak zwanego operatora zakresu. Jest to znak podwójnego dwukropka.
Przykład - zasłanianie zmiennych globalnych
int main() { .... int i, k=10; int* wsk = &k; for(i=0;i<10;i++) { .... int k = 5; // zasłaniamy zmienną lokalną k .... *wsk = 13; // zasłonięty obiekt jest dostępny // przy pomocy wskaźnika lub referencji } }
- W bloku pętli for zmienna lokalna k zasłania inną zmienną lokalną o takim samym identyfikatorze
- Zmienna lokalna nie jest dostępna przy pomocy swojego identyfikatora
- Obiekt zasłoniętej zmiennej lokalnej jest mimo wszystko dostępny, ale przy pomocy innych identyfikatorów. Mogą to być wskaźniki lub referencje.
Przykład - zasłanianie zmiennych lokalnych
- Modyfikator register informuje kompilator, że zależy nam na zapewnieniu możliwie szybkiego dostępu do zmiennej.
- Modyfikator ten można stosować tylko do zmiennych lokalnych i argumentów funkcji.
- W takim przypadku kompilator najczęściej stara się ulokować zmienną w rejestrze procesora.
- Nie ma gwarancji, że tak się stanie, jest to tylko nasze życzenie skierowane do kompilatora. W praktyce kompilator sam lepiej radzi sobie z optymalizacją kodu.
- Modyfikator volatile informuje kompilator, że zmienna może ulegać zmianom w sposób nieoczekiwany i niezależny od aktualnego procesu.
- Jest to możliwe w przypadkach obsługi przerwań, wieloprocesowości bądź wielowątkowości.
- Użycie volatile jest informacją dla kompilatora, że należy zachować ostrożność w przypadku optymalizacji kodu dotyczącego tej zmiennej.
W języku C/C++ słowo kluczowe void oznacza brak typu. Nie można deklarować zmiennych typu void.
Można natomiast deklarować wskaźniki typu void. O użyteczności wskaźników typu void przekonamy się w przyszłości, teraz podsumujemy ich własności.
-
Każdy wskaźnik może być przypisany do wskaźnika void, na przykład
int p; void* wsk = &p; int* q = &p; wsk = q;
- Nie jest dozwolona arytmetyka wskaźników void. Jest to uzasadnione, gdyż nie wiadomo jaki właściwie typ kryje się pod wskaźnikiem. Stąd nie wiadomo, czym miałoby być przesunięcie wskaźnika na następny obiekt.
Słowo kluczowe void jest również używane do deklaracji funkcji, które nie zwracają żadnej wartości. O tym powiemy już za chwilę.
Funkcja to podstawowy moduł programu w C/C++. Program główny to również funkcja o nazwie main. Funkcje mogą implementować algorytmy, realizować często powtarzające się zadania.
Nazwa funkcji musi być poprawnym identyfikatorem. Deklarując funkcję musimy podać, jakie są jej argumenty formalne, jaką ma nazwę oraz określić typ zwracanej wartości.
TypZwracany nazwaFunkcji(TypArgumentu1, ... ,TypArgumentuN); //przykłady void wypiszElementyTablicy(string t[], int ilosc); double poleProstokata(double bokX, double bokY);
Powyżej zadeklarowaliśmy funkcję o nazwie poleProstokata. Funkcja ta ma dwa argumenty typu double i zwraca również obiekt typu double.
Deklaracja funkcji jest tylko pouczeniem dla kompilatora, że nazwa funkcji jest poprawna. Nie powoduje to wygenerowania żadnego kodu wynikowego. Deklarację funkcji można powtórzyć dowolną ilość razy i nie spowoduje to błędów kompilacji czy linkowania.
Definicja funkcji zawiera ciało funkcji, czyli jej kod.
TypZwracany nazwaFunkcji(TypArgumentu1, ... ,TypArgumentuN) { // tutaj znajduje się kod funkcji } //przykład double poleProstokata(double bokX, double bokY) { return bokX * bokY; }
Definiując funkcję podajemy jej sygnaturę (czyli typ zwracany, nazwę i argumenty). Kod funkcji podajemy w nawiasach wąsiastych. Lista argumentów może być pusta.
Do zwracania wartości przez funkcję służy słowo kluczowe return.
- Standard języka C/C++ mówi, że funkcja main musi zwracać typ int.
- Chociaż niektóre kompilatory dopuszczają void jako typ zwracanej wartości przez funkcję main jest to błąd.
- Wartość zwracana przez funkcję main może być użyta przez system operacyjny lub inne programy, które uruchomiły ten program.
Przykład - funkcja licząca pole prostokąta.
Deklarując funkcję możemy pominąć nazwy argumentów pozostawiając jedynie typy argumentów.
double poleProstokata(double, double);
Argumenty umieszczone na liście w definicji funkcji to argumenty formalne. Kiedy wywołujemy funkcję w miejsce argumentów formalnych wstawiamy argumenty aktualne funkcji.
Mogą one być literałami (np. stałe wartości wprowadzone do kodu programu) lub zmiennymi, na przykład
double pole = poleProstokata(3,x);
- argumenty formalne funkcji są traktowane przez kompilator jak zmienne lokalne względem bloku funkcji.
- są one takiego typu, jaki podano na liście argumentów formalnych funkcji
- Argumenty formalne funkcji są traktowane jako zmienne lokalne wewnątrz bloku funkcji.
- W momencie wywoływania funkcji argumenty aktualne są kopiowane do argumentów formalnych.
- Mówimy wtedy o przesyłaniu argumentów do funkcji przez wartość.
Skoro argumenty aktualne są kopiowane, to oznacza, że funkcja pracuje na kopiach obiektów a nie na oryginalnych obiektach. Nie może więc zmodyfikować oryginalnych obiektów.
Przykład - argumenty przesyłane przez wartość.
Na liście argumentów formalnych funkcji mogą wystąpić zmienne wskaźnikowe. Tak jak każde zmienne są one przesyłane przez wartość.
void funkcja(int* argument);
Jeśli na liście argumentów formalnych funkcji znajduje się wskaźnik, to mówimy o przesyłaniu argumentu przez wskaźnik.
Przykład - argumenty przesyłane przez wskaźnik.
Na liście argumentów formalnych funkcji mogą wystąpić zmienne referencyjne. Pamiętajmy, że referencja to ukryty wskaźnik. Tak jak każde zmienne są one przesyłane przez wartość.
void funkcja(int& argument);
Jeśli na liście argumentów formalnych funkcji znajduje się referencja, to mówimy o przesyłaniu argumentu przez referencję.
Przesyłając argumenty przez referencję mamy możliwość modyfikacji oryginalnego obiektu, podobnie jak za pomocą wskaźnika. W przeciwieństwie do przesyłania argumentów przez wskaźnik nie musimy używać operatora wyłuskania.
Przykład - argumenty przesyłane przez referencję.
- Tablica, to stały wskaźnik - ustawiony na pierwszy element tablicy.
- W języku C/C++ nie da się przesłać do funkcji tablicy przez wartość - przesyłany jest zawsze wskaźnik
W poniższej deklaracji
void f(int t[5]);
do funkcji f zostanie przesłany adres początku pewnej tablicy. Sama funkcja nie wie, jakiej wielkości jest ta tablica, a podana wielkość nie ma znaczenia.
- Przesyłając tablicę do funkcji możemy pominąć jej rozmiar
- Funkcja nie wie, jakiej wielkości jest przesłana tablica. Zwykle przesyła się jej rozmiar w oddzielnym argumencie.
Mogłoby się wydawać, że funkcja powinna móc odczytać wielkość tablicy tylko na podstawie przesłanej tablicy. Pamiętajmy jednak o utożsamieniu tablic i wskaźników. Tak naprawdę funkcja może otrzymać jako argument tablicę, która jest fragmentem innej tablicy - jest to sytuacja bardzo typowa (np. przy sortowaniu)! Oczywiście rozmiar większej tablicy nie będzie poprawnym rozmiarem, który chcielibyśmy przesłać do takiej funkcji.
Przekazując tablicę do funkcji podajemy tylko jej nazwę.
void f(int t[]); void f(int* t); // to samo co wyżej int tablica[10]; f(tablica);
Przykład - przekazywanie tablicy do funkcji.
Argument formalny funkcji może być poprzedzony modyfikatorem const. Oznacza to, że po wywołaniu nie będzie można modyfikować takiego argumentu.
void f(const int& x, const int* y, const int z) { x += 5; // BŁĄD kompilacji, x jest stałą referencją *y += 5; // BŁĄD kompilacji, y jest wskaźnikiem do stałej z += 5; // BŁĄD kompilacji, z jest stałą y += 5; // przesunięcie wskaźnika jest poprawne }
Definiując funkcję należy zdecydować, w jaki sposób argumenty będą do niej przesyłane - przez wartość wskaźnik, czy referencję. Można stosować się do poniższych ogólnych zaleceń, ale są od nich liczne wyjątki
- obiekty typów wbudowanych zwykle przesyłamy przez wartość. Jest to o wiele szybsze niż dostęp za pomocą wskaźnika czy referencji
- obiekty typów wbudowanych przesyłamy przez referencję, jeśli chcemy modyfikować oryginalne obiekty
- tablice przesyłamy z użyciem wskaźnika do stałej (const T* tab), jeśli w funkcji nie modyfikujemy elementów tablicy
- obiekty typów zdefiniowanych przez użytkownika (na przykład obiekty klasy bibliotecznej string) zwykle przesyłamy przez referencję, aby uniknąć ich kopiowania. Jest to najczęstszy sposób używania referencji.
- obiekty typów zdefiniowanych przez użytkownika zwykle przesyłamy przez stałą referencję, jeśli tylko obiekt nie jest modyfikowany wewnątrz funkcji (jest tylko odczytu).
Przykład - modyfikator const w argumentach funkcji
Jeśli funkcja ma zwracaną wartość inną niż void to co najmniej raz w kodzie tej funkcji powinna wystąpić instrukcja return, za pomocą której zwracana jest wartość funkcji.
W takiej sytuacji po instrukcji return podajemy wyrażenie, które najpierw jest obliczane, a następnie staje się wartością zwracaną przez funkcję. Wyrażenie może być tylko stałą lub zmienną.
- Większość kompilatorów C/C++ nie przerywa kompilacji w przypadku braku instrukcji return w funkcji.
- Najczęściej zgłaszane jest ostrzeżenie i nie należy go lekceważyć!
Instrukcja return powoduje zakończenie wykonywania funkcji i zwrócenie wartości. Może być ona użyta dowolną ilość razy w kodzie funkcji.
W funkcjach, które deklarują brak zwracanej wartości (void) użycie instrukcji return nie jest potrzebne, ale możliwe. Wtedy po instrukcji return następuje tylko średnik. W takich funkcjach używa się return do zakończenia wykonywania funkcji, na przykład wewnątrz bloku instrukcji if, czy z instrukcji pętli.
Przykład - wartość zwracana przez funkcję.
- Obiekty zwracane przez funkcje i operatory, to tak zwane obiekty chwilowe.
- Obiekt chwilowy, to obiekt do którego mamy dostęp tylko w chwili jego utworzenia.
- Praktycznie wszystkie obiekty chwilowe powstają jako obiekty zwracane przez funkcje lub operatory, choć czasami obiekty typów wbudowanych powstają przy użyciu literałów.
- Jedyne co możemy zrobić z obiektem chwilowym, to przekazać go jako argument do innej funkcji.
- Po wywołaniu funkcji obiekt chwilowy jest likwidowany
- Obiekty chwilowe tworzone są automatycznie przez kompilator przy składaniu funkcji i operatorów: obiekt zwrócony przez funkcję zostaje argumentem aktualnym innej funkcji.
- Nie możemy zachować obiektu chwilowego dłużej niż na czas wywołania funkcji do której został przekazany, jednak przekazując obiekt chwilowy do operatora podstawienia możemy zachować jego kopię.
Funkcja może również zwracać wskaźnik lub referencję. Wtedy taki wskaźnik albo referencja jest obiektem chwilowym, a nie sam obiekt, na który taki wskaźnik pokazuje.
int* f(){ int* result; ...... return result; } const int& h(int& x){ ... return x; }
Zwykle za pomocą wskaźnika lub referencji zwraca się jeden z otrzymanych argumentów, który może być użyty jako argument dla innej funkcji albo wskaźniki/referencje do obiektów utworzonych na stercie.
nie należy zwracać referencji ani wskaźników do obiektów lokalnych w funkcji. Przestają one istnieć zaraz po zakończeniu funkcji. W związku z tym tak adres jak i referencja są nieaktualne.
int& f() { int k; .... return k; // BŁĄD! zwracamy referencję do zmiennej lokalnej }
Przykład - zwracanie wartości przez wskaźnik.
Wewnątrz ciała funkcji może wystąpić instrukcja wywołania tej samej funkcji. Mówimy wtedy o wywołaniu rekurencyjnym funkcji, albo o rekursji.
int funckja(int x, int y) { if(warunekKoncaRekursji) { return wartoscPoczatkowaRekursji; } // rób coś .... // wywołaj rekurencyjnie funkcja(a,b); // dowolną ilość razy funkcja(c,d); }
Aby nie doszło do zapętlenia programu, funkcja rekurencyjna musi zawierać wyrażenie warunkowe pozwalające na przerwanie rekurencyjnych wywołań.
- Zaletą rekursji jest prostota zapisu i relatywna łatwość analizy poprawności kodu opartego o rekursję
- Z tego powodu rekursja jest podstawowym narzędziem stosowanym w programowaniu funkcjonalnym
- Wadą rekurencji jest stosunkowo wolne wykonanie spowodowane narzutem związanym z częstym wywoływaniem funkcji oraz duże obciążenie pamięci.
Przykład - wyliczanie symbolu Newtona za pomocą rekursji.
Kompilator napotykając definicję funkcji zwykle generuje kod maszynowy tej funkcji. W czasie wykonywania programu kod ten jest ładowany do pamięci i umieszczany pod pewnym adresem.
Wywołanie funkcji powoduje skok do miejsca w pamięci, w którym jest umieszczona funkcja (wykonywanych jest jeszcze kilka innych czynności, które tutaj pomijamy).
Po zakończeniu wykonywania funkcji następuje powrót do miejsca, z którego nastąpiło wywołanie funkcji.
Przed nagłówkiem funkcji może pojawić się słowo kluczowe inline. Oznacza ono życzenie, aby kompilator zastąpił każde wywołanie funkcji jej ciałem. Powoduje to zniwelowanie całkiem sporego narzutu związanego z wywołaniem funkcji (skok, przekazywanie argumentów, itp.).
inline double Farenheit2Celsius(double f) { return (f-32)/9*5; }
- Takie funkcje nazywamy funkcjami inline
- Zadeklarowanie funkcji jako inline jest tylko sugestią dla kompilatora.
- Pożytek z deklarowania funkcji jako inline jest tylko w przypadku bardzo krótkich funkcji
- Funkcje inline są przykładem definicji odroczonych, dlatego najlepiej umieszczać je w plikach nagłówkowych
Jeśli w danym zakresie ważności mamy dwie lub więcej funkcji o takiej samej nazwie, to będziemy mówić o przeładowaniu nazw funkcji. Język C/C++ (i wiele innych języków) pozwala na definiowanie funkcji o takiej samej nazwie. Muszą się one różnić listą argumentów. Dozwolone jest przeładowanie, gdy
- jest inna ilość argumentów
- jest inna kolejność argumentów (nie są istotne nazwy argumentów formalnych, tylko ich typy!)
Nie można przeładować funkcji, jeśli różnią się tylko typem zwracanej wartości.
void sortuj(int t[], int rozmiarTablicy) { ... // tutaj algorytm sortowania liczb całkowitych } void sortuj(string t[], int rozmiarTablicy) { ... // tutaj algorytm sortowania napisów }
Przykład - przeładowanie nazw funkcji
Powiedzieliśmy, że przeładowanie funkcji jest możliwe, jeśli lista argumentów różni się typami lub kolejnością argumentów. Tutaj musimy uściślić, że w czasie przeładowania nie rozróżnia się pewnych typów, które formalnie są inne. Dotyczy to:
- T* i T[]
- T, const T, volatile T
Oznacza to na przykład, że następujące przeładowania spowodują błąd kompilacji
void f(int* t); void f(int z[]); void g(int x); void g(const int z);
Argumenty T i T& traktowane są jako tożsame tylko przez niektóre kompilatory. Jednak jeśli nawet uda się zdefiniować dwie funkcje różniące się tylko argumentem T i T&, to najczęściej przy próbie wysłania argumentu typu T do takiej funkcji kompilator sygnalizuje błąd niejednoznaczności.
Natomiast jako różne traktowane są dowolne dwa argumenty spośród następujących dwóch trójek
- T*, const T*, volatile T*
- T&, const T&, volatile T&
Jeśli mamy kilka funkcji przeładowanych, to kompilator może mieć problem z wyborem właściwej wersji. Postępuje one według reguł podanej poniżej i w takiej właśnie kolejności
- ścisła zgodność typów lub dopasowanie na zasadzie utożsamiania typów (np. int, const int)
- zgodność przy wykorzystaniu konwersji standardowych w zakresie typów całkowitych rozszerzających pojemność typu (np. int na long) oraz konwersja float na double
- zgodność z wykorzystaniem pozostałych standardowych konwersji, (np. int na double, int* na void*)
- zgodność przy wykorzystaniu konwersji zdefiniowanych przez użytkownika
Jeśli okaże się, że dwie lub więcej funkcji jest na tym samym poziomie zgodności, to sygnalizowany jest błąd niejednoznaczności (błąd kompilacji)
Przykład - niejednoznaczność przeładowania.
Deklarując funkcję, możemy przypisać argumentom na końcu listy ich wartości domyślne.
void wypisz(int t[], int dlugosc, char separator=','); void wypisz(int t[], int dlugosc, char separator) { .... // ciało funkcji }
Jeśli definicja i deklaracja są rozdzielone, to wartości argumentów domniemanych mogą się pojawić tylko w deklaracji. W przeciwnym razie zostanie zgłoszony błąd kompilacji.
Jeśli deklaracja jest połączona z definicją, to argumenty domniemane mogą się pojawić również w definicji funkcji.
Efekt użycia argumentów domniemanych jest taki, jak zdefiniowanie przeładowanych funkcji z różną ilością argumentów. W przykładzie powyżej będą to
void wypisz(int t[], int dlugosc, char separator); void wypisz(int t[], int dlugosc);
Definicje dla tych wersji kompilator uzupełni sam, na podstawie jednej podanej definicji i wartości domyślnych argumentów
- Jeśli w deklaracji funkcji podaliśmy wartość domyślną dla jakiegoś argumentu, to trzeba ją podać dla wszystkich kolejnych argumentów na liście
- Jeśli przy wywołaniu funkcji zdecydujemy się pominąć jakiś argument aktualny, który ma podaną wartość domyślną, to musimy pominąć wszystkie kolejne argumenty aktualne i zdać się na ich wartości domyślne
Przykład - argumenty domniemane funkcji
Język C/C++ dopuszcza tworzenie funkcji o nieokreślonej liczbie argumentów. Wprawdzie w C++ potrzeba używania takich funkcji jest znacznie ograniczona poprzez możliwość przesyłania do funkcji obiektów strukturalnych, jednak w czystym C było to i jest nadal ważnym mechanizmem tworzenia elastycznych funkcji.
Funkcja o nieokreślonej liczbie argumentów może przyjmować pewną stałą listę argumentów. Te opcjonalne umieszczane są na końcu i oznaczamy wielokropkiem, na przykład
int funkcja(int a, float b, char* typ,...);
Taki zapis oznacza, że funkcja zawsze oczekuje co najmniej trzech argumentów, które są kolejno typów int, float, char*. Później może wystąpić cokolwiek.
Aby skorzystać z mechanizmu przesyłania nieokreślonej ilości argumentów do funkcji należy dołączyć plik nagłówkowy cstdarg lub stdarg.h. Później schemat postępowania jest następujący
-
W pliku nagłówkowym cstdarg jest zdefiniowany typ va_list (nazwa pochodzi od variable-arguments list). Należy utworzyć zmienną tego typu. Załóżmy, że zmienna ta nazywa się ap (jest to tradycyjna nazwa takiej zmiennej, od argument pointer).
va_list ap;
- Wywołujemy funkcję biblioteczną va_start podając jako jej pierwszy argument utworzoną wcześniej zmienną typu va_list, a jako drugi argument zmienną odpowiadającą ostatniemu parametrowi obowiązkowemu definiowanej funkcji. Po deklaracji z ostatniego przykładu wywołanie miałoby zatem postać
va_start(ap,typ);
-
Wartości kolejnych argumentów odczytujemy wywołując funkcję va_arg: pierwszym jej argumentem powinna być zmienna ap, a drugim nazwa typu wartości odpowiedniego tego argumentu funkcji który chcemy odczytać.
Wynika z tego, że te typy trzeba znać! Trzeba też wiedzieć, kiedy skończyć wczytywanie argumentów. Najczęściej informacja o ich liczbie i typie przekazywana jest w jakiejś formie w pierwszych, obowiązkowych, argumentach funkcji.
double z = va_arg(ap,double);
- Wywołujemy funkcję va_end ze zmienną ap jako jedynym argumentem. Funkcja ta porządkuje stos, tak, aby powrócił on do stanu sprzed wywołania.
Przykład - zmienna liczba argumentów.
- Standard C++ nie specyfikuje w jakiej kolejności są ewaluowane argumenty aktualne funkcji.
- Poleganie na tej kolejności może prowadzić do ciężkich do usunięcia błędów
int licznik = 0; int f(){ return ++licznik; } int h(int a, int b){ cout << a << " " << b; } ... h(f(), f());
Po skompilowaniu funkcja jest umieszczona w pewnym miejscu w pamięci. Jej nazwa jest traktowana jako zmienna, która zawiera adres miejsca w pamięci, gdzie umieszczona jest ta funkcja.
Utożsamienie funkcji i wskaźnika pozwala na deklarowanie wskaźników do funkcji, co często bywa użyteczne.
int (*f)(int, float); int (*t[5])(int, float); void g( int (*)(double) );
W powyższym przykładzie
- f jest wskaźnikiem do funkcji, która ma argumenty typu int, float i zwraca int
- t jest pięcioelementową tablicą wskaźników do funkcji, które mają argumenty typu int, float i zwracają int
- g jest funkcją, której argumentem jest wskaźnik do funkcji o jednym argumencie typu double i zwracającą int
W celu podniesienia czytelności kodu można umieścić nazwy parametrów (są one ignorowane)
int (*f)(int ile, float dlugosc); int (*t[5])(int kierunek, float szybkosc); void g( int (*wskf)(double x) );
Przykład - wskaźniki do funkcji
Deklaracje wskaźników do funkcji można jeszcze bardziej skomplikować - np. funkcja, której argumentem jest wskaźnik do funkcji i zwraca wskaźnik do funkcji. Stają się one bardzo nieczytelne. Z pomocą przychodzi nam słowo kluczowe typedef
typedef służy do wprowadzania innej nazwy na istniejący już typ. Nowa nazwa musi być poprawnym identyfikatorem.
typedef unsigned long long ullong; ullong n=10;
W powyższym przykładzie zdefiniowaliśmy nowy typ o nazwie ullong. Od tej pory możemy używać tej nazwy na typ tak samo jak jej dłuższej wersji unsigned long long.
Analogicznie można zdefiniować typ wskaźnika do funkcji o określonej sygnaturze.
typedef bool (*WskaznikDoFuncji)(int,int); void funkcja(WskaznikDoFunkcji f) { ... bool r = f(a,b); } WskaznikDoFunkcji g(WskaznikDoFunkcji f) { ... bool r = f(a,b); return f; }
- W powyższym przykładzie zdefiniowaliśmy nowy typ WskaznikDoFunkcji.
- Zdefiniowaliśmy funkcję funkcja, której argumentem jest adres jakiejś funkcji o sygnaturze zgodnej z typem WskaznikDoFunkcji
- Zdefiniowaliśmy funkcję g, której argumentem jest adres jakiejś funkcji o sygnaturze zgodnej z typem WskaznikDoFunkcji. Zwraca ona wskaźnik do funkcji.
Przykład - wskaźniki do funkcji i typedef.
Pisząc
enum DzienTygodnia{nie,pon,wto,sro,czw,pia,sob};
definiujemy własny typ, tak zwany typ wyliczeniowy. Oczywiście można teraz zadeklarować
DzienTygodnia dzienWyplaty=pia;
Kompilator kojarzy z elementami typu wyliczeniowego kolejne liczby całkowite, poczynając od zera, chyba, że explicite przy definicji typu konkretny element skojarzono z inną liczbą, tak jak w przykładzie
enum controlKeys{tab=8,enter=13};
- Z każdym typem wyliczeniowym skojarzony jest możliwie najmniejszy zakres sięgający od zera do potęgi dwójki zmniejszonej o jeden. W praktyce jednak może z tym być róznie np. w gcc typy wyliczeniowe są przeważnie przechowywane jako int-y.
- Jednakże do zmiennej typu wyliczeniowego nie da się podstawić bezpośrednio liczby całkowitej. Trzeba dokonać jawnej konwersji. Tak więc zapis
powoduje błąd.
dzienWyplaty=4; // brak konwersji
- Jednak można napisać
choć w ten sposób nie przypisujemy żadnego dnia z listy, gdyż sobota to DzienTygodnia(6), a niedziela to DzienTygodnia(0). Dlatego dla bezpieczeństwa lepiej posługiwać się nazwami wartości.
dzienWyplaty=DzienTygodnia(7);
Powróćmy do naszego przykładu z bazą danych pracowników firmy. Do przechowywania informacji o pracownikach użyliśmy trójwymiarowej tablicy
char osoby[30][2][32];
Rozwiązanie takie ma pewne wady
- łatwo się pogubić w indeksach - trzeba pamiętać, co oznaczają poszczególne numery w tablicy
- marnotrawstwo pamięci - na ogół imiona są znacznie krótsze niż nazwiska (mogą być podwójne). Deklaracja tablicy trójwymiarowej narzuca konieczność przydzielenia takiej samej maksymalnej długości napisów dla wszystkich elementów tablicy
Język C dostarcza słowa kluczowego struct. Służy ono do tworzenia nowych, zdefiniowanych przez programistę typów. Najprostsza składnia jest następująca:
struct [OpcjonalnaNazwaStruktury] { // deklaracje zmiennych, z których składa się struktura } [opcjonalnieListaDeklarowanychZmiennych];
Definicja struktury musi kończyć się średnikiem! Brak średnika, to nagminny błąd nie tylko młodych programistów. Informacja o błędzie wyświetlana przez kompilator jest na ogół nie związana z linią programu, w której zapomnieliśmy średnika.
Struktura opisująca pracownika może wyglądać tak:
struct Pracownik { string imie; string nazwisko; string miejscowosc; string adres; string stanowisko; float pensjaPodstawowa; };
W powyższym przykładzie:
- Zadeklarowaliśmy nową strukturę o nazwie Pracownik.
- Stworzyliśmy nowy typ o nazwie Pracownik. Od tej pory można definiować zmienne i tworzyć obiekty tego typu.
- Nie zadeklarowaliśmy żadnej zmiennej typu Pracownik - lista zmiennych pomiędzy kończącym nawiasem a średnikiem jest pusta. Jest to typowa sytuacja.
- Kompilator nie wygeneruje żadnego kodu tak długo, aż nie użyjemy tej struktury w programie. Jest to tylko pouczenie dla kompilatora, że powstał nowy typ i można go będzie używać.
Struktury tworzymy po to, by deklarować zmienne strukturalne. Deklaracja zmiennej odbywa się tak samo jak każdej innej - podajemy typ i nazwę zmiennej lub zmiennych.
Pracownik p; Pracownik pracownicyFirmy[30];
- Pierwsza linia, to deklaracja jednej zmiennej typu Pracownik o nazwie p
- Druga linia to deklaracja 30-to elementowej tablicy, której elementami są struktury typu Pracownik
- Ilość pamięci, którą zajmuje cały obiekt opisywany przez strukturę można sprawdzić za pomocą operatora sizeof
cout << sizeof(Pracownik);
Przykład - struktura Pracownik
Deklarując zmienną strukturalną rezerwujemy pewien obszar pamięci o wielkości zależnej od tego, z czego składa się struktura. Pamięć ta jest podzielona na mniejsze fragmenty. Każdy z tych fragmentów ma rozmiar i odpowiadający wielkości pola składowego struktury. Pamięć ta jest interpretowana jako obiekt typu określonego w definicji struktury.
Do składowych struktury możemy się odwoływać za pomocą pól składowych struktury oraz notacji kropkowej.
Pracownik p; p.pensja = 7654.99;
Przykład - dostęp do pól składowych struktury
Jeśli mamy dostęp do struktury za pomocą referencji, to dostęp do składowych struktury uzyskujemy za pomocą notacji kropkowej.
Pracownik& p = * (new Pracownik); p.pensja = 6543.21;
W przypadku dostępu do obiektu strukturalnego za pomocą wskaźnika używamy notacji strzałkowej. Notacja ta odzwierciedla to, czym jest wskaźnik - zmienną pokazującą na inne obiekty.
Pracownik* p = new Pracownik; p->pensja = 6543.21;
Można również najpierw użyć operatora wyłuskania, a później zwykłej notacji kropkowej.
Pracownik* p = new Pracownik; (*p).pensja = 6543.21;
Przykład - dostęp do pól składowych struktury za pomocą wskaźników i referencji
Obiekty strukturalne są na ogół duże. Podczas przesyłania takich obiektów do funkcji jako argumentów zwykle wykorzystujemy przesyłanie przez referencję lub wskaźnik. Pozwala nam to uniknąć kopiowania dużych obiektów w czasie ich przesyłania do funkcji.
void wprowadz(Pracownik* p) { .... cin >> p->imie; .... } void wypisz(const Pracownik & p) { .... cout << p.imie; .... }
Przykład - przesyłanie obiektów strukturalnych do funkcji.
Obiekty strukturalne mogą być również zwracane przez funkcje jako wartości. Podlegają one tym samym regułom jak zmienne typów wbudowanych. Tworzony jest obiekt chwilowy, który staje się wartością funkcji. Może on być użyty jako argument innej funkcji lub zapamiętany w zmiennej za pomocą operatora przypisania.
Pracownik funkcja() { Pracownik p; ..... return p; }
- Obiekty zwracane w ten sposób są kopiowane!
- Należy być bardzo ostrożnym przy kopiowaniu obiektów strukturalnych zawierających składowe, które są wskaźnikami lub referencjami. Jak to należy poprawnie robić dowiedzą się Państwo na dalszych kursach (P1/P2). Na razie przyjmijmy, że funkcje nie zwracają przez wartość obiektów strukturalnych jeśli te zawierają pola wskaźnikowe lub referencyjne.
- Jeśli struktura ma składową, która jest tablicą statyczną (wielkość tablicy jest znana w czasie kompilacji), to jej (wygenerowane przez kompilator) kopiowanie wykona się poprawnie.
Nic nie stoi na przeszkodzie, aby wartością funkcji był wskaźnik lub referencja do obiektu strukturalnego.
Typową sytuacją jest zwracanie przez funkcję wskaźnika lub referencji do obiektu utworzonego na stercie.
Pracownik* utworz( const char imie[], const char nazwisko[], float pensja ) { Pracownik* p = new Pracownik; .... return p; }
Przykład - wskaźniki do obiektów strukturalnych jako wartość funkcji
Poniżej przedstawiamy zalążek programu realizującego prostą bazę danych o pracownikach firmy
- Proszę zwrócić uwagę, że program nie dostarcza interfejsu użytkownika (czyli menu z pytaniami w stylu: 1. Dodaj osobę, 2. Usuń osobę, itp). Jest to typowy sposób programowania.
- Interfejs użytkownika powinien być niezależnym od danych kawałkiem kodu. Operacje na danych mogą być oprogramowane i przetestowane bez jakiejkolwiek interakcji z użytkownikiem - wystarczą proste testy jednostkowe, tak jak to pokazano w przykładzie.
- W bazie zdecydowaliśmy się przechowywać tablicę wskaźników a nie tablicę obiektów. Ma to ogromne zalety:
- przechowujemy w pamięci tylko tyle obiektów, ile faktycznie istnieje
- w przypadku usuwania elementów z tablicy nie musimy kopiować danych - wystarczy skopiowanie adresu co najwyżej jednego obiektu na wolne miejsce
- w przypadku potrzeby powiększenia tablicy wystarczy skopiować tablicę adresów do nowej powiększonej tablicy, a nie całą tablicę obiektów. Wprawdzie podany program nie oferuje takiej możliwości, ale łatwo można go zmodyfikować, aby taką funkcjonalność dostarczał
- Obiekty strukturalne są przesyłane do funkcji przez wskaźnik - unikamy kopiowania obiektów.
Przykład - mini baza danych - programowanie z użyciem struktur
Zadaniem preprocesora jest dokonanie pewnych wstępnych posunięć przed rozpoczęciem kompilacji oraz sterowanie przebiegiem samej kompilacji.
Dyrektywa preprocesora ma składnię
#dyrektywa argumenty
- Dyrektywa nie kończy się średnikiem!
- Jeśli dyrektywa nie mieści się w jednej linii, można ją kontynuować w następnej, stawiając na końcu poprzedzającej linii ukośnik
- Rola preprocesora w samym programowaniu była większa w języku C.
- W języku C++ jego rola ogranicza się głównie do sterowania przebiegiem kompilacji
Dyrektywa makrodefinicji ma jedną z dwóch postaci
#define nazwa rozwinięcie #define nazwa(argumenty_formalne) rozwinięcie
- Nazwa makrodefinicji może być dowolnym dopuszczalnym w C++ identyfikatorem
- Zwyczajowo nazwa makrodefinicji budowana jest z samych dużych liter
- Skutkiem użycia dyrektywy makrodefinicji jest zastąpienie każdego wystąpienia podanej nazwy stosownym rozwinięciem.
- Rozwinięcie może mieć dowolną postać.
- Jeśli użyto argumentów, to każde wystąpienie nazwy wraz z zamkniętą w nawiasy listą argumentów aktualnych zostaje zastąpione treścią rozwinięcia, w którym dodatkowo każde wystąpienie argumentu formalnego zostaje zastąpione odpowiednim argumentem aktualnym.
- Między nazwą a nawiasem ( nie może być spacji!
- W języku C++ w większości przypadków w miejsce makrodefinicji można i warto używać tak zwanych szablonów
- Szablony to coś w rodzaju makrodefinicji, które jednak rozwijane są przez sam kompilator, a nie przez preprocesor
- Unika się w ten sposób wielu błędów pojawiających się na skutek braku dobrej współpracy pomiędzy preprocesorem, a kompilatorem.
- Poprzedzenie argumentu makrodefinicji w jej rozwinięciu znakiem # powoduje zastąpienie argumentu literałem znakowym zawierającym argument aktualny.
- Na przykład
#define WYPISZ(x) cout << #x << "=" << x << "\n"; int i=7; WYPISZ(i)
spowoduje wypisanie na standardowym wyjściu
i=7
Przykład - zamiana argumentu na łańcuch
- Przy rozwijaniu makrodefinicji każde wystąpienie ## zamieniane jest na tekst pusty
- Pozwala to utworzyć nowy identyfikator przez dopisanie jakichś znaków alfanumerycznych przed i/lub po argumencie będącym identyfikatorem.
- Technika taka przydaje się do tworzenia skrótów przy wypisywaniu serii spokrewnionych deklaracji
- W przykładzie
makrodefinicja TEKST(alfa) deklaruje spokrewnioną parę zmiennych:
#define TEKST(a) char* a##_wskaznik; int a##_dlugosc; TEKST(alfa); TEKST(beta); TEKST(gamma);
char* alfa_wskaznik; int alfa_dlugosc;
Uwaga: preprocesor nie sprawdza sensowności argumentów, więc na przykład TEKST("alfa") wygeneruje linię
char* "alfa"_wskaznik; int "alfa"_dlugosc;
na której wywróci się dopiero sam kompilator.
Przykład - sklejanie identyfikatorów
W języku C makrodefinicje miały duże zastosowanie ze względu na brak technik programowania za pomocą szablonów. Obecnie makrodefinicje stosuje się głownie do
- definiowania pustych nazw wykorzystywanych do sterowania pracą kompilatora
- definiowania stałych (w C++ niewskazane)
#define pi 3.14 - unikania konieczności przepisywania jednakowo działających funkcji różniących się jedynie typem argumentów (w C++ niewskazane)
#define max(a,b) ( a>b ? a : b) .... i=max(i,2); x=max(x,3.14);
#define INTEL
- Język C++ proponuje lepsze metody definiowania stałych (const) i makrodefinicji z argumentami (template), więc w C++ użycie makrodefinicji powinno być ograniczone tylko do pierwszego przypadku.
- Wyjątkiem są makrodefinicje wykorzystujące zamianę argumentu na łańcuch i sklejanie identyfikatorów, które przydają się nie tylko w C, ale i w C++
Dyrektywa kompilacji warunkowej ma postać
#if warunek // linie kompilowane warunkowo #endif
- Warunek musi mieć postać, która gwarantuje, że jego rozstrzygnięcie jest możliwe już na etapie kompilacji.
- Jeśli warunek jest spełniony, linie zawarte między dyrektywami #if i #endif są kompilowane, a w przeciwnym razie są pomijane
Dyrektywa ta może wystąpić również w wersji
#if warunek // linie kompilowane gdy warunek zachodzi #else // linie kompilowane gdy warunek nie zachodzi #endif
Typowym zastosowaniem jest kompilacja zależna od procesora, systemu operacyjnego lub interfejsu użytkownika.
#if GUI == 1 #include <windows.h> .... #else .... #endif
Przykład - kompilacja warunkowa
W warunku dyrektywy #if można wykorzystać systemową makrodefinicję
defined(nazwa)
sprawdzającą czy podana nazwa została zdefiniowana
Czasami zdarza się, że pewna nazwa zdefiniowana w jakiejś bibliotece koliduje z naszym planem użycia tej nazwy. Wtedy może przydać się dyrektywa
#undef nazwa
która powoduje wymazanie z pamięci kompilatora wcześniej wyuczonej nazwy.
Dyrektywa włączenia pliku pozwala na włączenie do kompilowanego pliku dokładnie w miejscu wystąpienia tej dyrektywy zawartości innego pliku.
Dyrektywa włączenia pliku ma jedną z dwóch postaci
#include <nazwa_pliku> #include "nazwa_pliku"
- Pierwsza postać stosowana jest do włączania plików bibliotecznych dostarczanych wraz z kompilatorem
- Druga postać stosowana jest do włączania pozostałych plików
Formalna różnica pomiędzy tymi formami sprowadza się do ustalenia kolejności w jakiej są przeszukiwane katalogi i zależy od kompilatora.
- Przy skomplikowanym układzie zależności pomiędzy włączanymi plikami może dojść do sytuacji, że jeden plik jest włączany więcej niż jeden raz w trakcie jednej kompilacji.
- Niepotrzebnie obciąża to kompilator, a czasami może prowadzić do błędów.
- By tego uniknąć powszechnie stosuje się następujące rozwiązanie, w którym treść pliku zostaje obłożona dyrektywą warunkowej kompilacji
#ifndef JEDNOZNACZNY_OPIS_PLIKU #define JEDNOZNACZNY_OPIS_PLIKU // zawartość pliku #endif
W trakcie pracy preprocesora dostępne są następujące nazwy, których rozwinięcie definiuje sam preprocesor.
- __LINE__ - określa numer linii, nad którą preprocesor w danym momencie pracuje
- __FILE__ - nazwa aktualnie kompilowanego pliku
- __DATE__ - data kompilacji
- __TIME__ - czas kompilacji
Przykład - użycie nazw predefiniowanych
Jako przykład funkcji o nieokreślonej licznie argumentów przedstawimy funkcje biblioteczne printf, scanf. Funkcje te realizują niskopoziomowe (a więc szybkie) operacje wejścia-wyjścia. Są ona dostępne po włączeniu pliku nagłówkowego cstdio.
Pierwszym argumentem printf jest napis, który może zawierać znaki sterujące, określające sposób interpretowania argumentów z listy argumentów o zmiennej długości. Najprościej zilustrować to na przykładzie
char towar[] = "chleb"; int ilosc=30; float cena=2.99; printf("Towar %s, ilosc %d, cena %f",towar,ilosc, cena);
Funkcja printf wypisuje na standardowe wyjście podany napis jednocześnie analizując jego zawartość. Znaki rozpoczynającej się od % to znaki specjalne. Każde wystąpienie takiego znaku będzie zastąpione kolejnym argumentem z listy podanym w czasie wywołania. Sposób interpretacji określają kody (litery): %s dla napisu, %d dla liczby całkowitej, %f dla liczby zmiennoprzecinkowej.
Szczegółowa dokumentacja funkcji jest bardzo długa - można ją znaleźć na przykład tutaj.
Funkcja scanf to funkcja realizująca niskopoziomowe czytanie. Jej format odpowiada funkcji printf - pierwszym argumentem jest napis, w którym kodujemy co chcemy przeczytać, kolejne argumenty to adresy obiektu, w których zostaną umieszczone przeczytane dane.
int i; float liczba; char bufor[100]; scanf("%d%f%s",&i,&liczba,bufor);
Przykład - funkcje wejścia-wyjścia
Pierwszym argumentem funkcji printf i scanf jest tekst, który decyduje o sposobie w jaki będą wypisywane kolejne argumenty. Może on zawierać znaczniki formatujące postaci
%[flagi][szerokosc][.precyzja][modyfikator]typ
| typ | oczekiwany typ argumentu | Wyjście | Przykład |
|---|---|---|---|
| c | char | znak | a |
| d lub i | int | liczba całkowita ze znakiem w zapisie dziesiętnym | 392 |
| e lub E | float | liczba w notacji naukowej | 3.9265e+2 |
| f | float | liczba rzeczywita z przecinkiem | 392.65 |
| g lub G | float | liczba rzeczywista (format zależny do ilości cyfr znaczących) | 392.65 |
| s | const char * | tekst | sample |
| u | unsigned int | liczba całkowita bez znaku w zapisie dziesiętnym | 7235 |
| x lub X | unsigned int | liczba całkowita bez znaku w zapisie szesnastkowym | 7fa lub 7FA |
| p | wskaźnik | adres pamięci | B800:0000 |
Flagi
| flaga | znaczenie |
| - | wyrównanie do lewej (do prawej jest domyślne), |
| + | wymusza znak + przed liczbami dodatnimi, |
| spacja | wstawia spację przed liczbami dodatnimi, |
| 0 | jeżeli liczba jest, któtsza niż podana długość to uzupełnia zerami (domyślnie spacjami) |
-
Jeżeli
szerokosc została podana to dany argument zostanie wypisany przynajmiej na tylu znakach (dodatkowe znaki będą spacjami lub zerami). Wyjście nie zostanie jednak obcięte. precyzja dla liczb zmiennoprzecinkowych określa liczbę cyfr po przecinku, które zostaną wypisane, dla liczb całkowitych określa minimalną liczbę cyfr, dla łańcuchów znakowych jest to maksymalna liczba znaków które zostaną wypisane. - Jeżeli zamiast liczby w miejsce szerokosci lub precyzji wpiszemy * to odpowiednia wartość powinna zostać podana na liście argumentów przed formatowanym argumentem,
modyfikator zmienia znaczenie znacznika typ. Modyfikator h zmiejsza zakres typu, modyfikatory l,L zwiększają zakres typu. np. %hd oznacza short int, %ld - long int, %lf double, %Lf long double
Przykład - Formatowanie wyjścia
Funkcje do operacji na plikach znajdziemy w pliku nagłówkowym cstdio.
Typowy sposób pracy z plikiem, to:
- Otwarcie pliku
- Zapis/Odczyt danych
- Zamknięcie pliku
Do otwierania i zamykania plików służą funkcje
FILE * fopen ( const char * filename, const char * mode ); int fclose ( FILE * stream );
Jak widać funkcja otwierająca plik ma dwa argumenty
- filename - to nazwa otwieranego pliku
- mode - to parametry określające tryb otwarcia pliku. Jest to napis zawierający ciąg liter, które mają następujące znaczenie
- r - otwórz plik tylko do czytania
- w - otwórz plik tylko do zapisywania
- a - otwarcie pliku w trybie dopisywania na koniec zawartości
- r+ - otwarcie istniejącego pliku w trybie odczytu i zapisu
- w+ - otwarcie pliku w trybie odczytu i zapisu do nadpisywania. Jeśli plik wcześniej istniał, to jego zawartość zostanie usunięta.
- a+ - otwarcie do dopisywania i czytania. Otwarcie (lub stworzenie jeśli nie istnieje) do poprawiania na końcu pliku.
- t - plik zostanie otwarty w trybie tekstowym
- b - plik zostanie otwarty w trybie binarnym
Funkcja fopen zwraca wskaźnik do struktury FILE opisującej plik lub wskaźnik NULL, jeśli nie udało się utworzyć pliku. Typowe otwarcie pliku może wyglądać tak:
FILE* file=fopen("plikTekstowy.txt","w+t"); if(file==NULL) { printf("Nie moge otworzyc pliku!"); } else { .... // operacje na pliku fclose(file); }
Uchwyt (wskaźnik) pliku jest argumentem funkcji fclose, którą należy wywołać po zakończeniu operacji na pliku.
Plik tekstowy, to plik który zawiera dane przetłumaczone na format czytelny dla człowieka. Tekst może być formatowany w linie i akapity (tak jak w edytorze tekstowym), liczby są zamieniane na napisy (pamiętajmy, że w pamięci komputera liczby są przechowywane w postaci binarnej) i drukowane do pliku. Odczyt takiej liczby wymaga analizy napisu zawartego w pliku i zamiany go na liczbę. Operacje na plikach tekstowych są wolne, ale ich zawartość jest "czytelna".
Zapis do pliku można realizować przy pomocy funkcji
int fprintf ( FILE * stream, const char * str, ... );
Jej składnia jest prawie taka sama jak omówionej wcześniej funkcji printf. Różnią się tym, że funkcja fprintf ma dodatkowy argument - uchwyt pliku, do którego chcemy zapisywać. Poza tym sposób zapisu do liku jest taki jak na ekran.
Odpowiednikiem funkcji scanf dla plików jest fscanf
int fscanf ( FILE * stream, const char * str, ... );
Przykład - zapis i odczyt pliku w trybie tekstowym
Wyjście nieformatowane jest dużo szybsze gdyż podany łańcuch tekstowy nie jest interpretowany. Odpowiedni łańcuch tekstowy powinien przygotować programista samodzielnie np. dokonując odpowiednich konwersji.
Zapis do pliku odpowiednio znaku lub łańcucha tekstowego realizujemy przez
int fputc (char c, FILE * stream); int fputs (const char * str, FILE * stream);
Odpowiedni aby przeczytać jeden znak lub łańcuch tekstowy możemy użyć funkcji
int fgetc (char c, FILE * stream); int fgets (const char * str, int num, FILE * stream);
Druga z funkcji czyta num-1 znaków z strumienia stream chyba, że wcześniej napotka znak końca lini lub końca pliku.
Pliki binarne zawierają dane w takiej postaci, w jakiej są przechowywane w pamięci komputera. Jest to po prostu zrzut fragmentu pamięci komputera. Zawartość pliku na ogół jest nieczytelna dla człowieka - widzimy zwykłe "krzaki".
Operacje na plikach binarnych są szybkie gdyż nie musimy konwertować danych z tekstu na ich właściwy format. Jeśli tylko człowiek nie musi czytać i rozumieć zawartości pliku, to preferowane jest zapisywanie w formacie binarnym. Dane w pliku binarnym traktowane są jak ciąg bajtów.
Biblioteka C/C++ dostarcza funkcji odczytywania i zapisywania zbioru bajtów. Są to
size_t fread ( void * ptr, size_t size, size_t count, FILE * stream ); size_t fwrite ( const void * ptr, size_t size, size_t count, FILE * stream );
Argumenty w tych funkcjach oznaczają:
| Nazwa | Opis |
| ptr | miejsce w pamięci skąd/dokąd będą zapisywane dane |
| size | rozmiar pojedynczego elementu odczytywanego/zapisywanego |
| count | ilość odczytywanych/zapisywanych elementów |
| stream | uchwyt pliku, na którym ma być wykonana operacja odczytu/zapisu |
Przykład - zapis i odczyt w trybie binarnym
Istnieje cały szereg innych funkcji do operacji na plikach binarnych, w tym funkcji wyszukujących, przesuwających wskaźnik pliku, itd. Listę tych funkcji i ich opisy można znaleźć w sieci, na przykład tutaj.
Czytając lub zapisując do pliku automatycznie przesuwamy wskaźnik aktualnej pozycji w pliku. Ale możemy ten wskaźnik także przesuwać "ręcznie".
Aktualną pozycję w pliku możemy odczytać korzystając z funkcji
long int ftell ( FILE * stream ); int fgetpos ( FILE * stream, fpos_t * position );
Aby sprawdzić czy osiągnięty został koniec pliku możemy użyć funkcji
int feof(FILE * stream);
Jeżeli osiągnieto koniec pliku to kolejne operacje na pliku nie będą miały efektu chyba, że użyjemy jedna z funkcji
void rewind( FILE * stream ); int fseek ( FILE * stream, long int offset, int origin ); int fsetpos ( FILE * stream, const fpos_t * pos );
- Funkcja rewind przesuwa wskaźnik pliku na jego początek.
- Funkcja fseek przesuwa wskaźnik na pozycję daną przez offset licząc od
- początku pliku jeżeli origin==SEEK_SET
- końca pliku jeżeli origin==SEEK_END
- bieżącej pozycji jeżeli origin==SEEK_CUR
Do tej pory używaliśmy pliku nagłówkowego iostream i strumieni cin, cout do realizacji czytania z klawiatury i wypisywania na ekran. Podamy teraz nieco więcej szczegółów dotyczących realizacji tych operacji.
W C++ operacje wejścia-wyjścia są realizowane za pomocą strumieni. Strumień możemy sobie wyobrażać jako strumień danych (bajtów) płynący od źródła do ujścia. Źródłem może być klawiatura, plik, pamięć, modem, potok nazwany, gniazda, skaner, .... Ujściem może być ekran, drukarka, plik, pamięć, ....
W bibliotece są zdefiniowane dwa podstawowe rodzaje strumieni
- input stream - strumienie odpowiadające za czytanie danych, używane gdy nasz program chce mieć dostęp do ujścia strumienia danych
- output stream - strumienie odpowiadające za wysyłanie danych, używane gdy nasz program chce być źródłem dla strumienia danych
Wśród tych dwóch kategorii biblioteka standardowa dostarcza klas realizujących szczególne rodzaje operacji wejścia-wyjścia
- istream - ogólna nazwa na wszystkie strumienie wejściowe (dla zaawansowanych - jest to klasa bazowa dziedziczona w pozostałych strumieniach). Szczególnym rodzajem są
- istringstream - strumień wejściowy, gdzie źródłem danych jest pamięć. Dostępny po włączeniu pliku nagłówkowego sstream
- ifstream - strumień wejściowy, gdzie źródłem danych jest plik. Dostępny po włączeniu pliku nagłówkowego fstream
- ostream - ogólna nazwa na wszystkie strumienie wyjściowe. Szczególnym rodzajem są
- ostringstream - strumień wyjściowy, gdzie ujściem danych jest pamięć. Dostępny po włączeniu pliku nagłówkowego sstream
- ofstream - strumień wyjściowy, gdzie źródłem danych jest plik. Dostępny po włączeniu pliku nagłówkowego fstream
Po dołączeniu któregoś z plików nagłówkowych iostream, sstream, fstream mamy do dyspozycji predefiniowane cztery strumienie
- cin - strumień typu istream, powiązany ze standardowym wejściem (stdin), zwykle jest to klawiatura
- cout - strumień typu ostream, powiązany ze standardowym wyjściem, zwykle jest to ekran. Strumień ten jest buforowany, co oznacza, że dane pojawiają się na ekranie z pewnym opóźnieniem.
- cerr - strumień typu ostream, powiązany ze standardowym strumieniem komunikacji o błędach (stderr), zwykle jest to ekran. Strumień ten nie jest buforowany.
- clog - strumień typu ostream, powiązany ze standardowym strumieniem komunikatów, raczej rzadko używany. Jest buforowany.
cout << "Napis";
operator<< (cout, "Napis");
Pozwala to na rozszerzenie funkcjonalności także na nasze własne typy. Wystarczy dla naszego typu np. Towar przeładować funkcję
std::ostream & operator<< (std::ostream & strumien, const Towar & t);
Potem możemy wypisywać nasz typ dokładnie tak samo jak typy wbudowane
Towar kielbasa; cout << kielbasa << endl;
Przykład - wypisywanie własnych typów
Dla każdego ze strumieni możemy ustawić flagi, które będą decydują o sposobie działania strumienia np. w jaki sposób dane są formatowane przy wypisywaniu na ekran.
Flagi zdefiniowane w klasie bazowej
| Flaga | Grupa | Znaczenie |
|---|---|---|
| skipws | Podczas wczytywania będą ignorowane białe znaki. | |
| left right internal |
adjustment | Określa sposób wyrównywania (justowania) odpowiednio do lewej, prawej oraz przez wstawienie znaków wypełniających na ustalonej wewnętrznej pozycji np.
-7
-7
- 7 |
| dec oct hex | basefield | Decyduje w jakim systemie będą wypisywane i wczytywane liczby, odpowiednio: dziesiętnym, ósemkowym, szesnastkowym. |
| showbase | Decyduje czy dla liczb ósemkowych i szesnastkowych będą dodawane odpowiednie przedrostki 0 i 0x | |
| uppercase | Decyduje czy w zapisie liczb będą stosowane dużelitery np. 0X1FA23, 1.244E-12 | |
| showpoint | Kropka dziesiętna będzie zawsze wypisywana a po niej odpowiednia liczba cyfr (nawet jeżeli są zerami) | |
| scientificfixed | floatfield | Określa sposób wypisywania liczb zmiennoprzecinkowych: naukowy (scientific) lub dziesiętny (fixed). Jeżeli żadna z flag nie jest ustawiona to sposób wypisywania zależy od liczby i ustawionej precyzji. |
| unitbuf | decyduje czy dany strumień jest buforowany |
Stan flag strumienia możemy zmienić używając metod setf oraz unsetf
cout.setf(ios::showpoint); cin.unsetf(ios::skipws);
Dla flag występujących w grupie możemy użyć metody setf(flaga, grupa), która nie tylko ustawi daną flagę ale także wyzeruje pozostałe flagi w danej grupie.
cout.setf(ios::hex, ios::basefield);
Aby określić minimalną szerokość na jakiej należy wypisać daną liczbę czy tekst możemy użyć metody
cout.width(20); cout << 7.12 << endl;
char nazwa[20]; cin.setw(20); cin >> nazwa;
Metoda
float x = 0.123456789, y = 2; cout << x << " " << y << endl; // 0.123456 2 cout.precision(8); cout << x << " " << y << endl; // 0.12345678 2 cout.setf(ios::showpoint); cout << x << " " << y << endl; // 0.12345678 2.00000000
Dużo wygodniejszym sposobem zmiany formatowania jest wykorzystanie tzw.
Zamiast pisać
cout.setf(ios::showpoint|ios:fixed); cout.precision(10); cout.width(20); cout << 124.43225425 << endl;
możemy napisać
cout << showpoint << fixed << setprecision(10) << setw(20); cout << 124.43225425 << endl;
| Manipulator | Znaczenie |
|---|---|
| setprecision(n) | Ustawia dokładność wypisywania liczb zmiennoprzecinkowych. |
| setw(n) | Ustawia szerokość pola dla danych wejściowych oraz wyjściowych. |
| skipws noskipws | Podczas wczytywania będą (nie będą) ignorowane białe znaki. |
| left right internal |
Określa sposób wyrównywania (justowania) odpowiednio do lewej, prawej oraz przez wstawienie znaków wypełniających na ustalonej wewnętrznej pozycji np.
-7
-7
- 7 |
| dec oct hex | Decyduje w jakim systemie będą wypisywane i wczytywane liczby, odpowiednio: dziesiętnym, ósemkowym, szesnastkowym. |
| showbase | Decyduje czy dla liczb ósemkowych i szesnastkowych będą dodawane odpowiednie przedrostki 0 i 0x |
| uppercase | Decyduje czy w zapisie liczb będą stosowane dużelitery np. 0X1FA23, 1.244E-12 |
| showpoint | Kropka dziesiętna będzie zawsze wypisywana a po niej odpowiednia liczba cyfr (nawet jeżeli są zerami) |
| scientific fixed | Określa sposób wypisywania liczb zmiennoprzecinkowych: naukowy (scientific) lub dziesiętny (fixed). Jeżeli żadna z flag nie jest ustawiona to sposób wypisywania zależy od liczby i ustawionej precyzji. |
| endl | Wstawia znak końca wiersza i opróżnia bufor strumienia wyjściowego. |
| flush | Opróżnia bufor strumienia. |
| ws | Odczytuje oraz ignoruje białe znaki. |
Biblioteka języka C++ dostarcza operacji strumieniowych na plikach (tak tekstowych jak i binarnych) za pomocą strumieni. Aby skorzystać z tych klas należy dołączyć plik nagłówkowy fstream.
ifstream plikDoOdczytu; plikDoOdczytu.open("nazwaPliku.txt"); plik >> zmienna; plikDoOdczytu.close();
Jak widać w powyższym przykładzie operacje na plikach tekstowych traktowanych jako strumienie wygląda tak samo jak korzystanie ze strumieni cin, cout. Przy otwieraniu pliku możemy posłużyć się manipulatorami do ustalenia trybu otwarcia pliku. Tryby te można ze sobą łączyć za pomocą alternatywy bitowej. Na przykład
ofstream myFile; myFile.open("f.bin",ios::app | ios::binary); myFile.write(dane,rozmiar); myFile.close();
W powyższym przykładzie manipulator ios::app oznacza, że plik jest otwarty do dopisywania (append), ios::binary oznacza otwarcie pliku w trybie binarnym.
Przykład - odczyt plików za pomocą strumieni
Instytutu Informatyki i Matematyki Komputerowej UJ
Daniel Wilczak